Benchmark de différents models pour le code

On va tester différents model IA pour le code: Claude, Codex, Deepseek, GLM et KIMI K2 Thinking et vous verrez des résultats surprenants.
Dernièrement j'ai voulu benchmarker les models IA pour le code, les tester sur un projet similaire et voir la différence de comportement.
Je peux déjà vous dire que le test que je leur ai fait faire a l'air de leur être familier. Parce que tous ont fait une fenêtre de rendu et un style de rendu assez similaire. Comme s'ils s'étaient entraîné à le faire. Comme s'ils avaient déjà vu l'exercice. Et pour cause, je ne leur ai pas demandé un truc très original, voici le prompt de base:
Fais un Tetris jouable dans un navigateur web avec Phaser en Typescript et en utilisant Vite.js
Tous les models utilisés ont reçu ce même prompt, mais vous verrez il y a autant de similitude que de différence par la suite.
Les models utilisés:
- Claude Opus 4.6
- GPT Codex 5.3
- Deepseek Reasoner 3.2
- GLM 5
- Kimi K2 Thinking
Le protocole de test est le suivant:
- Claude code pour Opus 4.6 (l'application officielle d'Anthropic)
- Codex pour GPT Codex 5.3 (l'application officielle d'OpenAI)
- Opencode pour Deepseek, GLM et Kimi K2
Génération d'un Tetris avec l'IA
Claude Opus 4.6
Commençons par Opus 4.6, le fleuront du développement web par IA. Il s'agit sincèrement du meilleur model mais il requiert au moins l'abonnement à 90€ /mois pour en profiter et au mieux celui à 180€. Donc, vu le prix, on est obligé de le mettre en concurrence.
Voici le résultat obtenu:
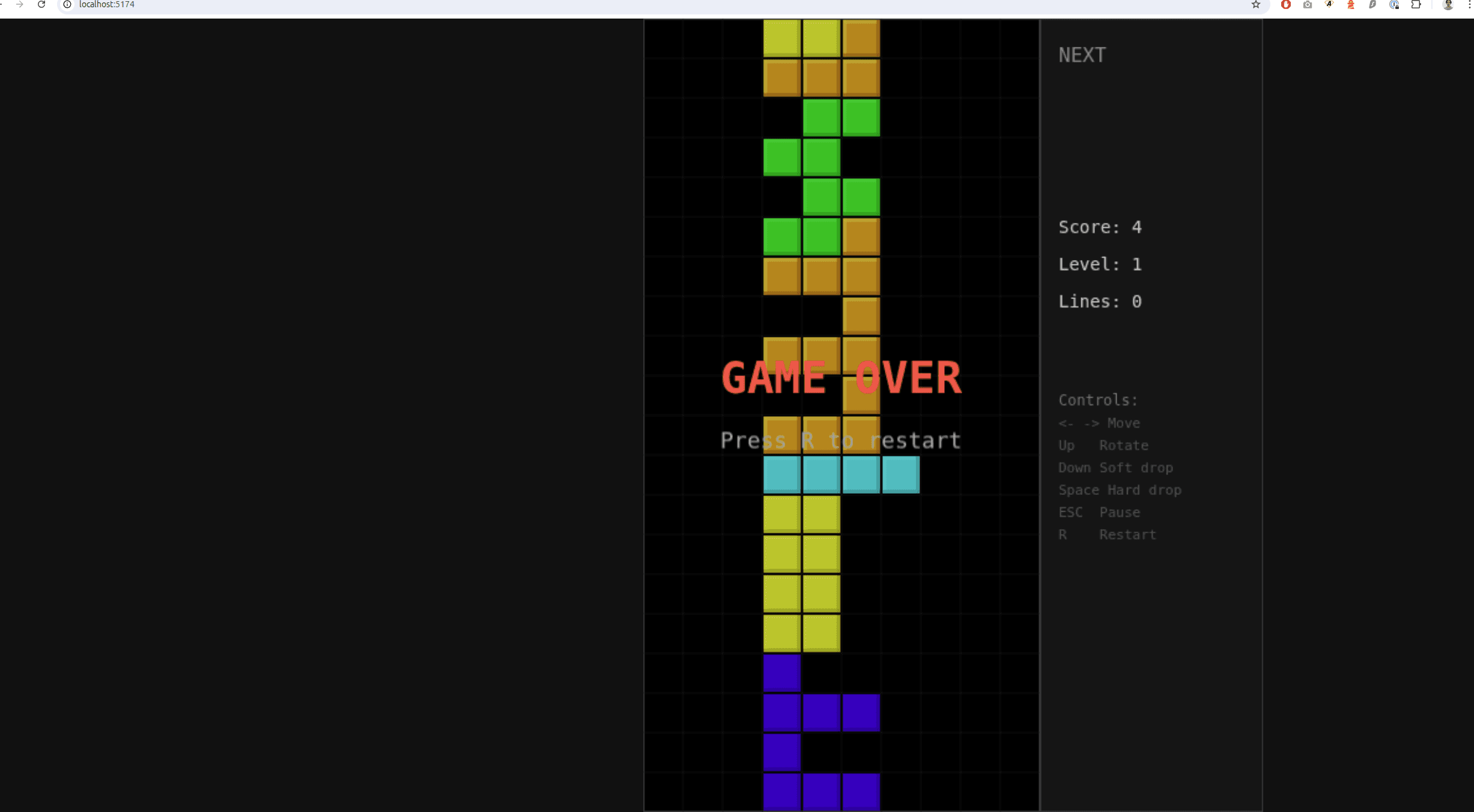
Visuellement, celui de Claude avait un rendu plutôt bon, dès le premier essai. Alors l'UI n'est pas optimisée et très propre, le code également est mono fichier, mais le résultat est là. Maintenant à l'utilisation, j'avais quelques soucis:
- Le maintien des touches ne fonctionnait pas
- J'avais des bugs si je maintenais la touche down du clavier qui est sensé accélérer la chute (saccades)
On va dire qu'on obtient un résultat proche de ce qu'on voulait de 8/10.
Après, un rapide prompt, il a tout fixé et ça se comporte mieux.
GPT Codex 5.3
Voici le résultat obtenu avec GPT Codex 5.3:
Au premier run, il a fait quelque chose d'épuré, toujours un mono fichier et pas de réelle organisation du code.
Mais à l'usage, ça ne fonctionnait pas, aucune pièce chutait. Apparemment, il se serait trompé dans l'index de profondeur de rendu et faisait le rendu des pièces derrière la grille, donc je ne voyais pas ce qu'il se passait...
Là encore, un simple prompt a suffit à corriger le problème mais ce n'était pas vraiment le résultat attendu et ce n'était pas jouable au premier run.
Si je devais noter je mettrais un 2/10 au premier run pour l'interface et le code. Mais après sa correction on va dire 7/10, mais il aura fallu 2 prompts.
GLM 5
Voici le tetris codé par GLM 5 depuis Opencode:
Alors on le voit, le rendu est tronqué et il manque une partie du contenu comme s'il avait mis une size sur la fenêtre de rendu et que le contenu était plus grand que la largeur autorisée.
Egalement, au premier run, j'avais le rendu (tronqué) mais aucune touche ne fonctionnait, je ne pouvais rien faire du tout.
Après un second prompt, j'ai récupéré les touches mais pas le rendu complet.
De même, il m'a fait le bug de Claude Opus, c'est à dire que je ne pouvais pas maintenir les touches et il a fallu un 3ème prompt.
On va dire que c'est passable 5/10.
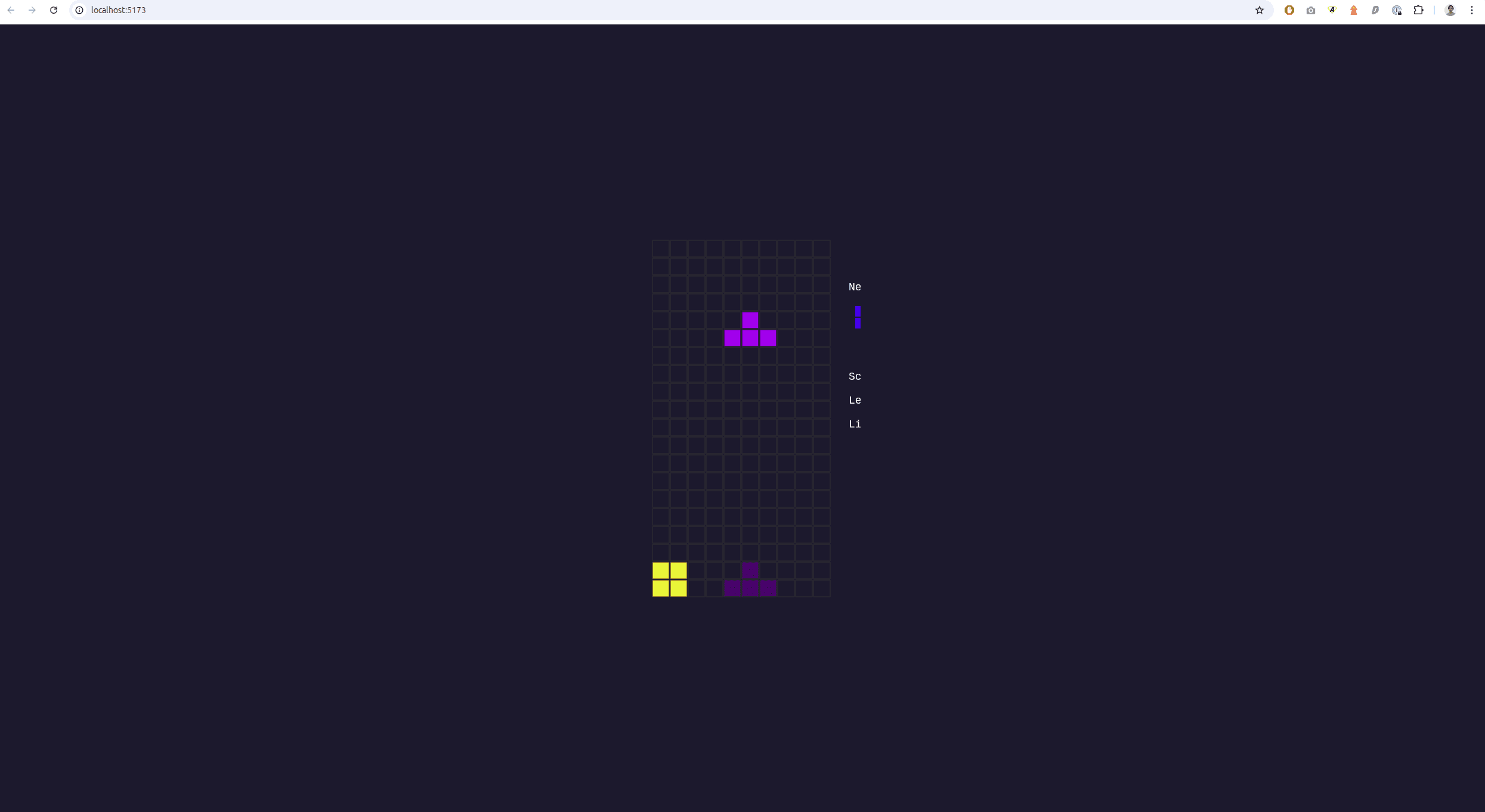
Kimi K2 Thinking
Je sais que Moonshot AI a sorti son Kimi 2.5, mais je le referai plus tard. En attendant, voici le Tetris codé par Kimi K2 Thinking:
Entre nous, c'est le pire rendu qu'on ait eu de toutes les IA testés. Je lui ai demandé de corriger son rendu et après un autre prompt, ça n'a rien changé.
J'ai des touches mais un rendu désastreux...
Et pire, c'est le seul qui m'a fait un jeu injouable, parce que la touche qui sert à pivoter la pièce plante le jeu.
Donc le rendu est désastreux et c'est injouable: 1,5/10
Deepseek Reasoner 3.2
De tous, je trouve sincèrement que c'est celui qui m'a le plus surpris, là encore il n'est pas parfait, loin de là mais je vous explique...
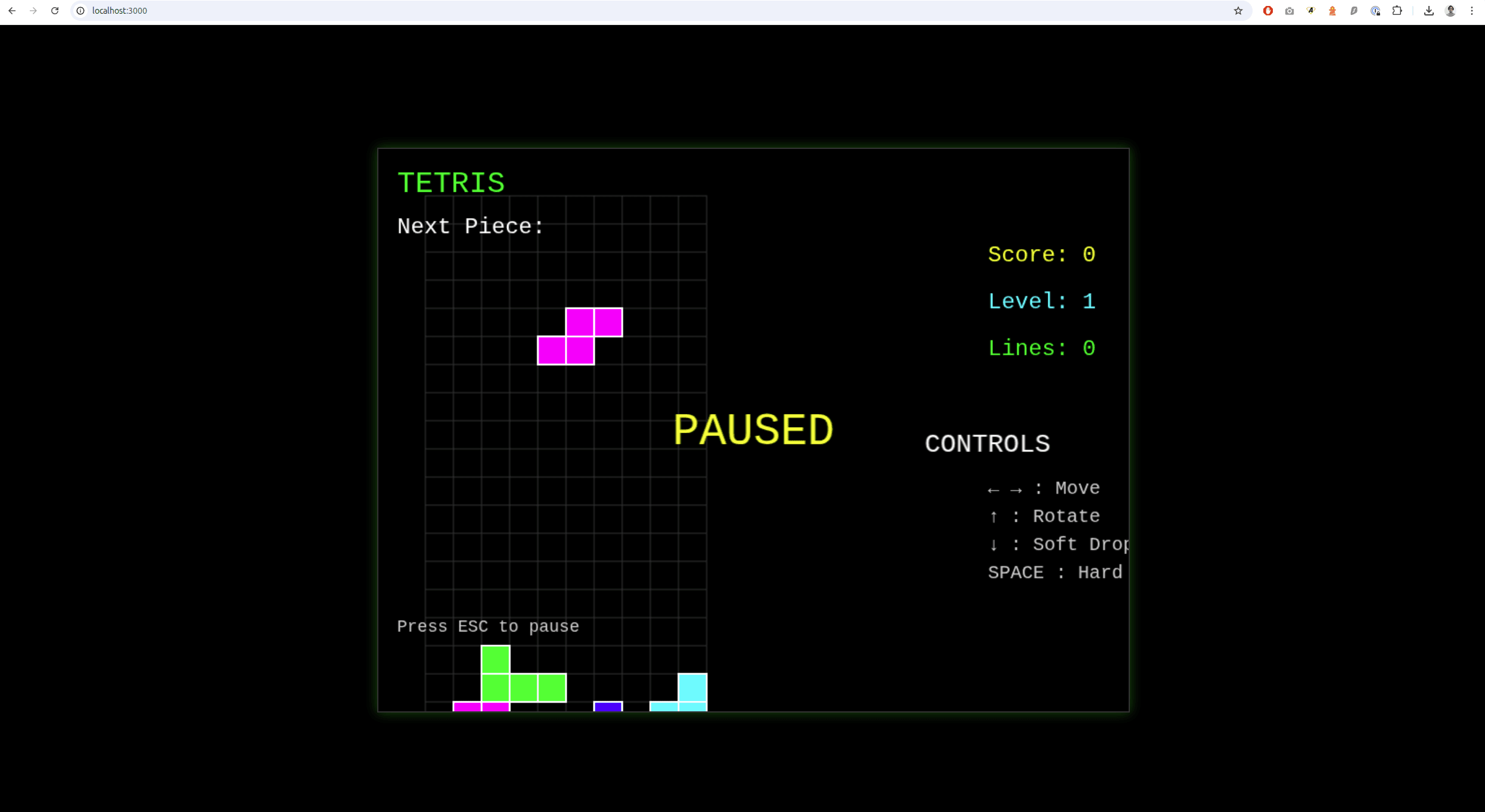
Le premier rendu que m'a fait Deepseek était un peu buggy. Il avait fait une hauteur de rendu inférieur au contenu, qu'il a fini par corriger au second prompt.
En revanche, lui avait 100% du jeu fonctionnel, je lui mets 8,5/10.
Qu'est-ce que j'en pense ?
Voici le repository si vous voulez jeter un oeil au code: https://github.com/aluzed/tetris-phaser-ai .
Maintenant faisons le bilan de tout ça:
En moyenne, tous les modèles ont prix environ 5 minutes pour générer le jeu (au premier prompt).
Claude, le meilleur modèle n'a pas fait quelque chose de parfait (tout comme les autres), mais je vous fait remarquer qu'il ne coûte pas 2, ou 3 fois plus cher, il est presque 5 fois plus cher qu'un ChatGPT Codex. Gardez bien ça en tête.
Codex n'est pas mauvais, il n'est pas parfait, mais coute 20€/mois avec l'abonnement ChatGPT et ils offrent le double de token jusqu'au 2 Avril.
Je sais que ce n'est pas comparable à Claude car il y a tout de même des différences de compétences (comblés avec le temps), mais il se débrouille bien et on peut commencer avec ce plan abordable sur Codex, alors que Claude avec l'abonnement à 20€ on atteint trop rapidement les limites.
Maintenant, les modèles chinois qui aiment se targuer d'être meilleurs que les autres ou au même niveau pour beaucoup moins cher, etc... Je dois vous dire que c'est souvent du bullshit.
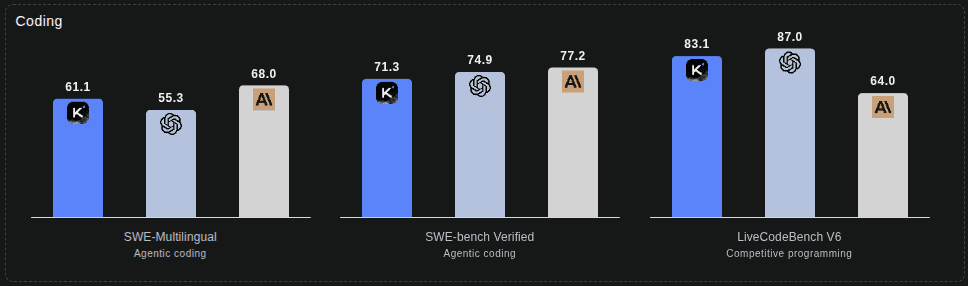
Faîtes attention quand vous voyez ce genre de charts en ligne, et ces comparatifs basés sur des benchmarks. Sachez que les modèles s'entraînent souvent sur ces benchmarks jusqu'à connaître les réponses par coeur.
Tiens tiens, ça me fait penser aux gens à l'école qui avaient des 19,5/20 et sorti de ce cadre, quand ils arrivent dans la vie active, n'arrivent jamais à résoudre les problèmes aléatoires; car il n'y pas de par coeur possible...
La vérité, c'est que face à un nouveau problème, c'est souvent Claude qui devance tout le monde.
GLM et Kimi sont 2 models bullshits.
GLM parle souvent de son pricing intéressant vis à vis de Claude. Et ce n'est pas difficile, Claude coûte littéralement un bras, donc effectivement on peut faire moins cher, mais au détriment de la qualité.
GLM reste le model qui, lors de mes tests, m'a fait le plus de trucs WTF au monde:
- ne pas respecter les instructions
- faire des choses que je n'ai pas demandé
- tourner en boucle sur des solutions testés (j'ai dû l'arrêter manuellement)
Ayant 3 mois de GLM Pro à 40€ je teste au maximum ses capacités, et c'est un welcome offer; donc ils veulent que je passe à 80€ dans 3 mois. Autant vous dire que cela ne se fera pas, parce que je ne compte pas garder ce modèle, beaucoup trop limité en terme de capacité.
Parlons maintenant de 2 models que j'ai utilisé au coût d'API: Deepseek et Kimi K2 Thinking.
Pour générer ce Tetris, voici les prix:
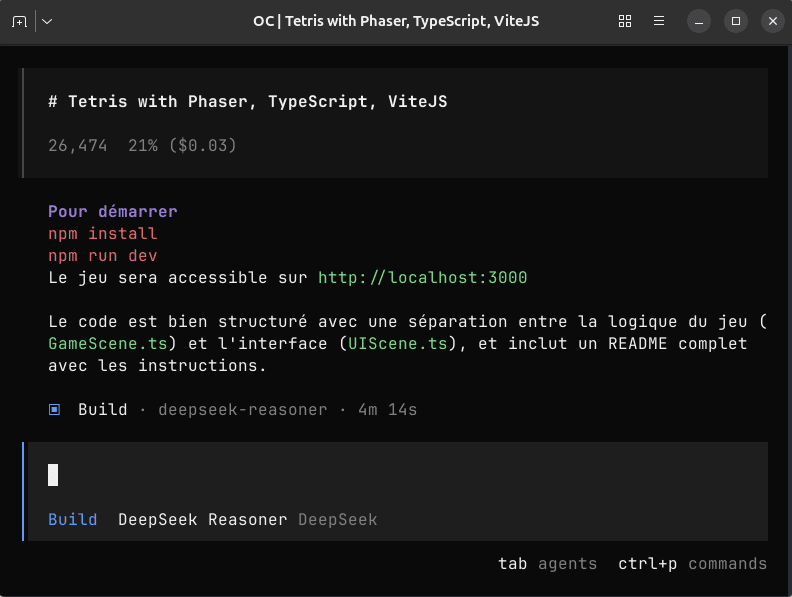
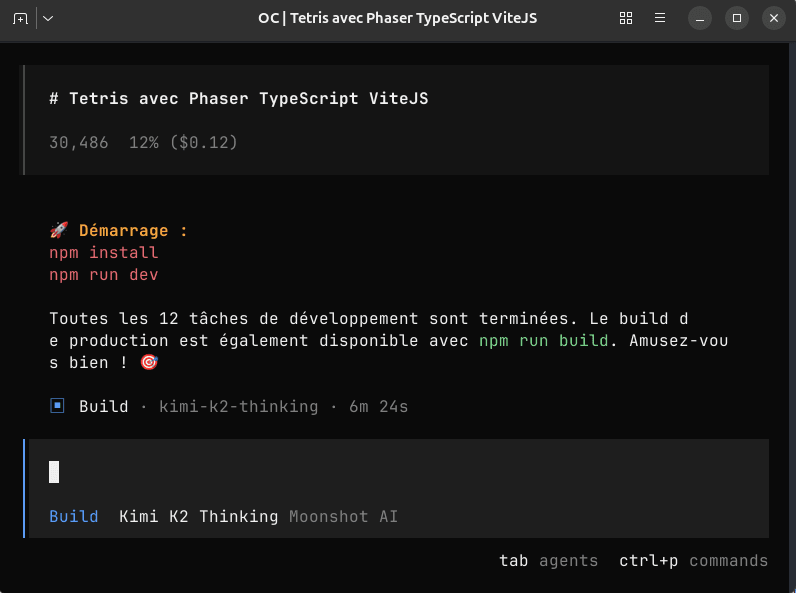
Deepseek m'aura coûté 3 cents et Kimi K2 aura couté 12 cents.
Ce n'est pas grand chose, mais vous observerez déjà une différence de 4 fois le prix, avec un Deepseek qui gagne haut la main car Kimi m'a fait un truc injouable.
Et le grand gagnant de tout ça, au rapport qualité prix, c'est Deepseek, c'est pourquoi je vous parle souvent de lui et je pense que sa version 4 va être un game changer.
Je continue de penser que Claude est devant, mais pour la différence de prix et sur des tâches plus petites, si vous êtes patients Deepseek étant un peu plus lent mais beaucoup moins cher est une bonne alternative. Codex, si vous avez un plan ChatGPT s'en sort très bien également et je pense le garder dans le temps.
Les autres modèles en revanche sont souvent décevants, que ce soit GLM ou Kimi, ils ne jouent clairement pas dans la même cour, pourtant, ils disent tout l'inverse dans leur communication et dans leurs charts. Donc faîtes attention à votre portefeuille, ça n'en vaut probablement pas la peine.
Et je souhaite conclure en disant, Tetris est un jeu très populaire et ce que j'ai demandé fait peut être partie de ce sur quoi ces modèles ont été entraînés. Il n'y a qu'à voir les rendus très proches, les couleurs différentes pour chaque pièces, les instructions affichés, la fenêtre "Next", etc... Il y a un pattern commun qui montre que ces models ont déjà fait ce que j'ai demandé. Donc, il ne faut pas prendre ce test pour argent comptant, mais faire aussi des benchmarks de votre côté pour vous en assurer.
FAQ
Claude est vraiment 5 fois plus cher que Codex, ça vaut le coup quand même ?
Claude reste techniquement devant, surtout face à des problèmes nouveaux, mais la différence de résultat sur ce test ne justifie pas forcément l'écart de prix. Pour des tâches courantes, Codex à 20€/mois ou Deepseek en API à quelques centimes peuvent suffire largement.
Deepseek est vraiment si bon pour si peu cher ?
Sur ce benchmark, Deepseek a obtenu la meilleure note (8,5/10) avec un jeu 100% fonctionnel dès le deuxième prompt, pour seulement 3 centimes d'API. Il est un peu plus lent que Claude, mais le rapport qualité/prix est difficile à battre.
Les modèles chinois comme GLM ou Kimi tiennent-ils vraiment leurs promesses ?
Dans ce test, non. GLM a nécessité trois prompts successifs et présente des comportements erratiques, tandis que Kimi K2 a produit un jeu injouable malgré les corrections demandées. Les comparatifs flatteurs qu'ils affichent reposent souvent sur des benchmarks sur lesquels les modèles se sont entraînés, ce qui ne reflète pas leurs performances réelles.
Est-ce que ce benchmark est vraiment représentatif des capacités de ces modèles ?
Pas entièrement. Tetris est un exercice très connu et les modèles ont probablement été entraînés sur des exemples similaires, ce qui explique les rendus proches. Pour une évaluation fiable, il vaut mieux tester aussi avec des problèmes spécifiques à votre propre contexte.
Quel modèle choisir si on débute et qu'on a un budget limité ?
Codex avec un abonnement ChatGPT existant est un bon point d'entrée, ou Deepseek en accès API si vous acceptez une légère lenteur. GLM et Kimi sont à éviter au vu des résultats obtenus ici.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.
Poursuivre la lecture

