Benchmark géant des models IA

Benchmark de 14 modèles IA sur la recréation du jeu Frogger avec un prompt identique. Les résultats sont surprenants...
Update 22-05-2026: Ajout de Qwen 3.7 Max
Avec la multitude de models IA disponible aujourd'hui, j'ai voulu faire un benchmark équitable pour les départager.
Modalités du benchmark
Pour ce bench, on va tester exactement le même prompt sur différents models, pas une virgule de plus.
Il s'agit du jeu rétro Frogger qui parlera peut être aux plus anciens d'entre vous.
Pourquoi un jeu rétro ?
Parce que c'est simple, rapide car en 2D.
Donc, ça ne va pas non plus cramer 200k tokens. Il n'est pas question de refaire FC 26 ou Forza.
Est-ce que c'est un bon test ?
Honnêtement, ça parait bête mais oui, je m'explique:
- Vous avez la gestion des animations (autonome)
- La gestion des timings
- La gestion des states (vie, temps, score)
- La gestion des collisions
On est vraiment pas mal pour du benchmark agentique.
Quels sont les critères d'évalutations ?
- la taille du livrable (à quel point l'IA a écrit du code)
- la durée de run pour coder ce projet
- le prix de l'output
- le graphisme sur 10
- la qualité de code sur 10 (respect des best practices, usage de patterns, DRY, factorisation, code propre, nommage des vars et des functions)
- l'expérience in-game
Une chose m'a frappé pendant les tests.
Ce benchmark m'a rappelé à l'époque des portages consoles où la qualité des jeux était très différente d'une machine à l'autre car les budgets de code étaient différents et le hardware aussi était aussi hétérogène.
Or, ici, il s'agit du même prompt à l'identique, de ma machine, mais une puissance de calcule provenant de différents datacenter et des modèles propriétaires ou opensource de qualité hétérogène également.
Pour info, à chaque fois que j'ai eu le choix sur le thinking mode, j'ai toujours choisi "high" pour tous les models.
Autre précision, j'ai le plan Max pour Codex et Claude, c'est pourquoi il n'y a pas les prix. Mais je pense que globalement on est sur moins de 1$ pour ce prompt.
On attaque ?
Deepseek v4 Flash
C'est le Deepseek le moins cher aujourd'hui et vous allez voir qu'il se débrouille déjà bien pour un model open source.
Résultat

Scores
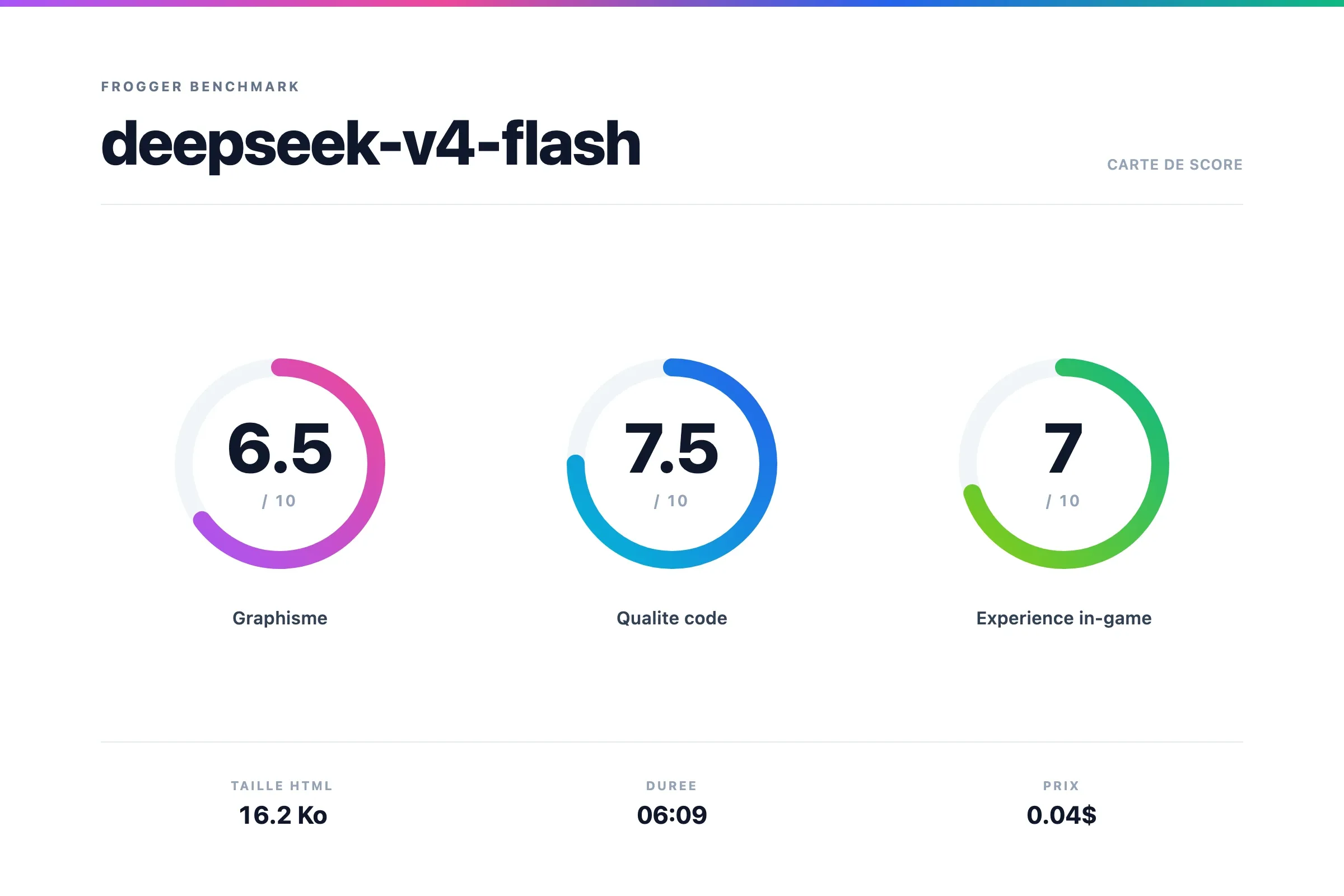
Verdict Deepseek v4 Flash
C'est pas mal, pour un model aussi peu couteux. Alors oui, j'ai quelques problèmes de collision ici et là.
Mais ça va, ça reste jouable.
Deepseek v4 Pro
C'est le Deepseek le plus haut de gamme aujourd'hui mais qui reste un model très abordable et open source.
Résultat
Scores
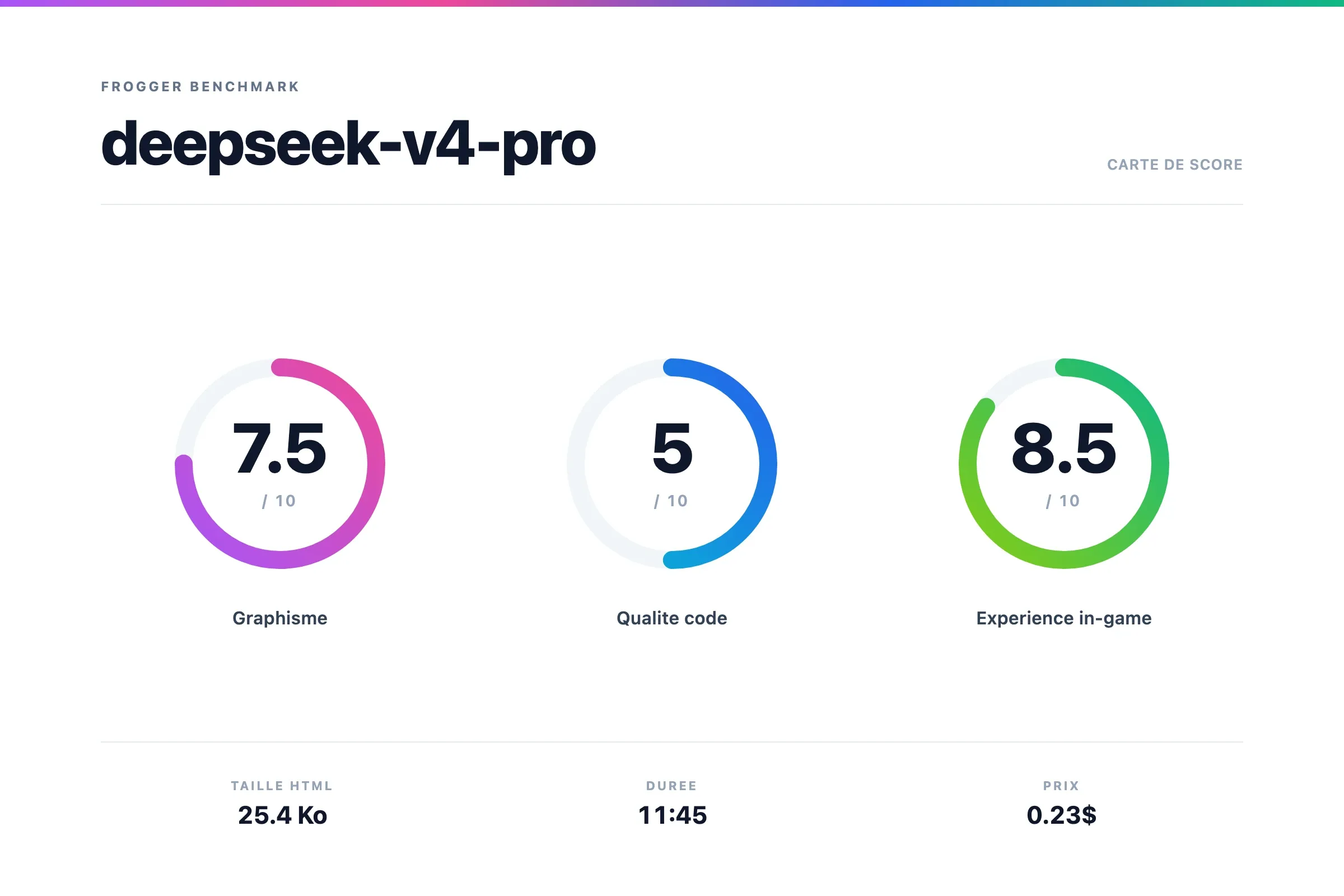
Verdict Deepseek v4 Pro
J'ai beaucoup aimé l'expérience. Très fun !
Gemini 3.5 Flash
C'est le Gemini dont Google nous a vanté les mérites. Je ne doute pas qu'il a de bons côtés, mais voyons plutôt...
Résultat
Scores
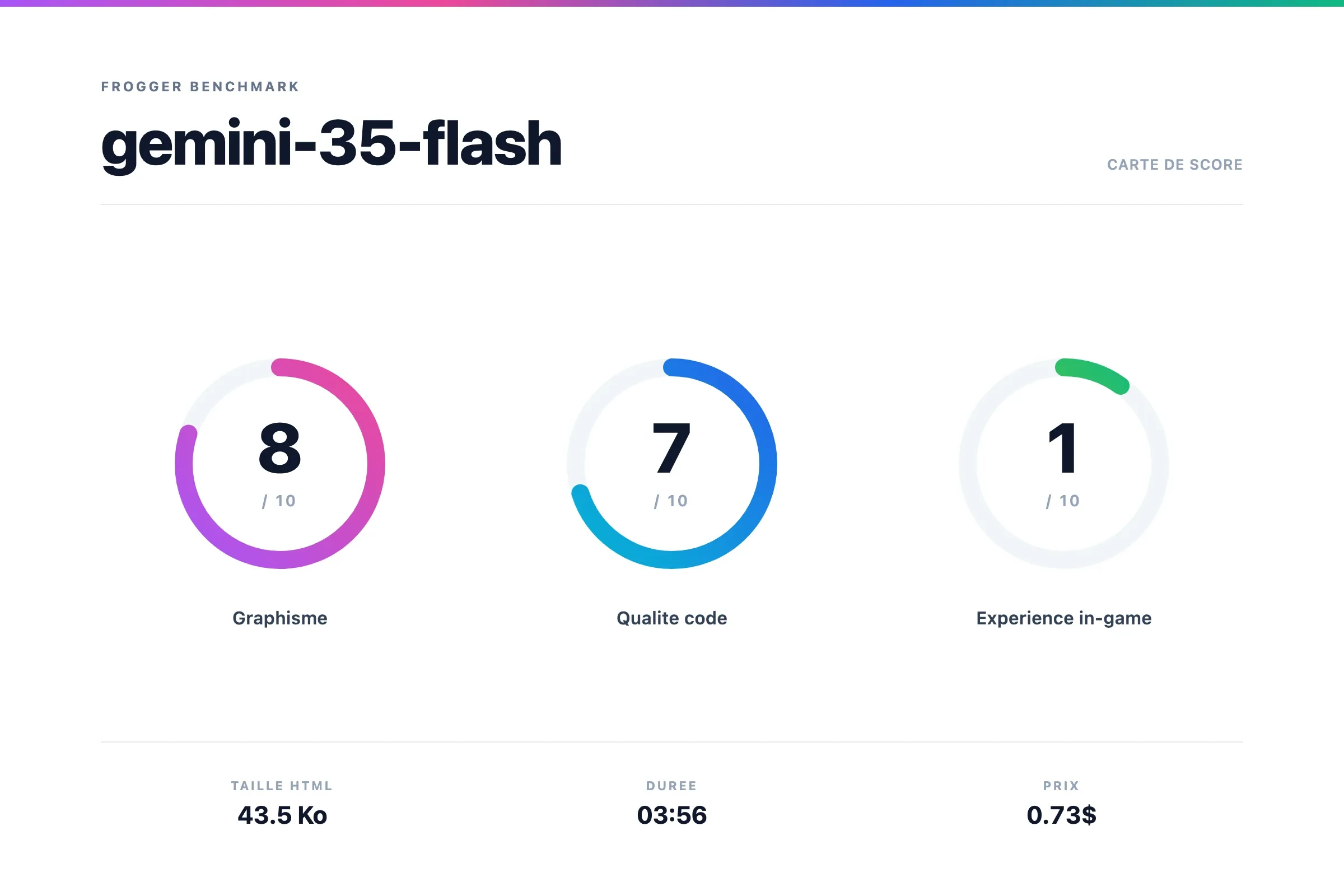
Verdict Gemini 3.5 Flash
Grosse déception ! Le pétard mouillé... 🤣 Le jeu est buggy, complètement figé. Alors c'est beau, mais on ne peut rien faire.
GLM 5.1
Z.AI aime mettre en avant son model open source GLM sur tous les benchmarks du monde.
Il se retrouve souvent au coude à coude avec Opus sur ces benchmarks. Mon petit doigt me dit que certains models s'entraînent carrément sur ces fameux benchmark. Mais voyons voir.
Résultat
Scores
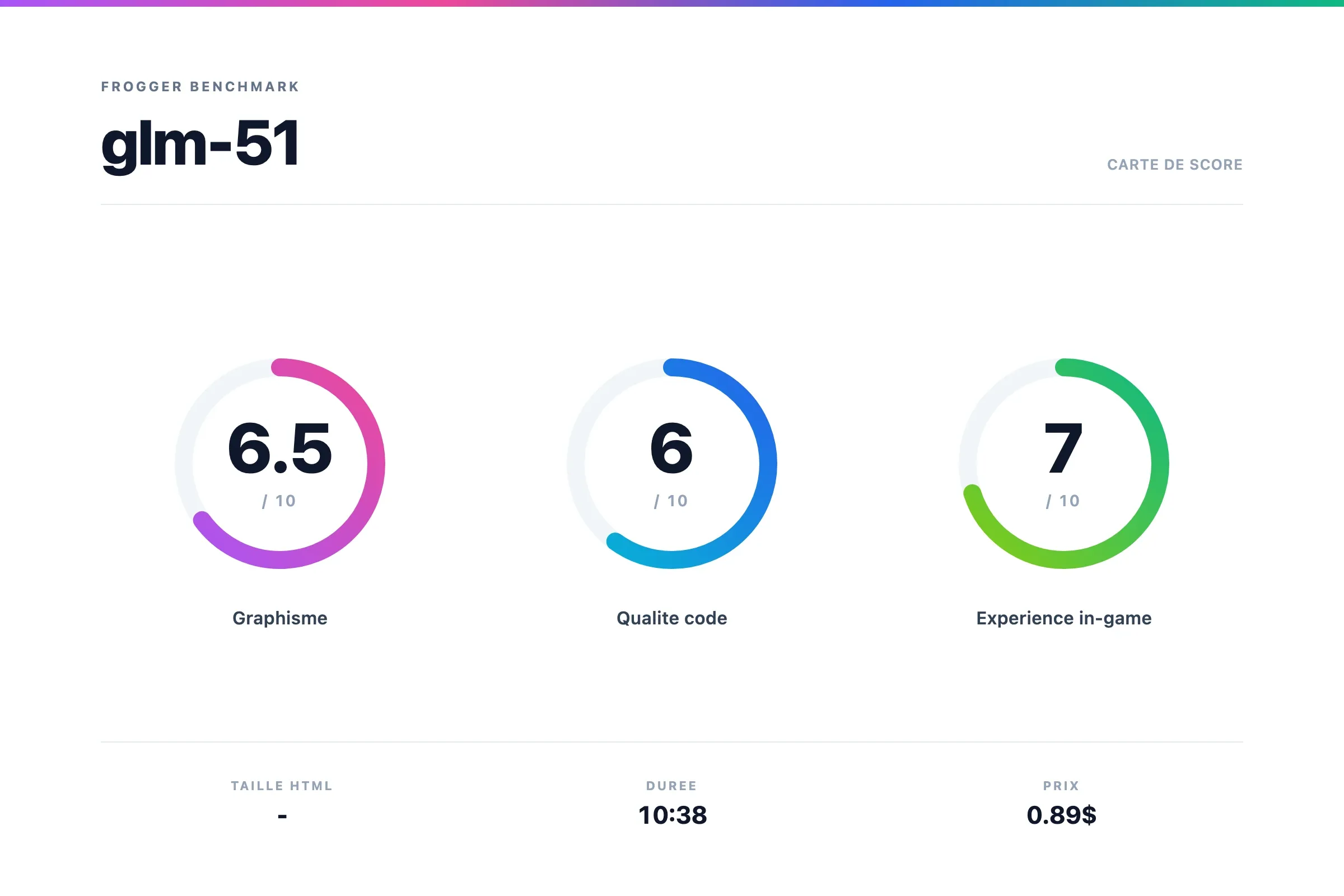
Verdict GLM 5.1
Vraiment pas mal, j'ai eu quelques bugs de collision à cause des timings mais rien de dramatique.
GPT 5.4 Mini
Une version low cost et "rapide" de GPT 5.4.
Résultat
Scores
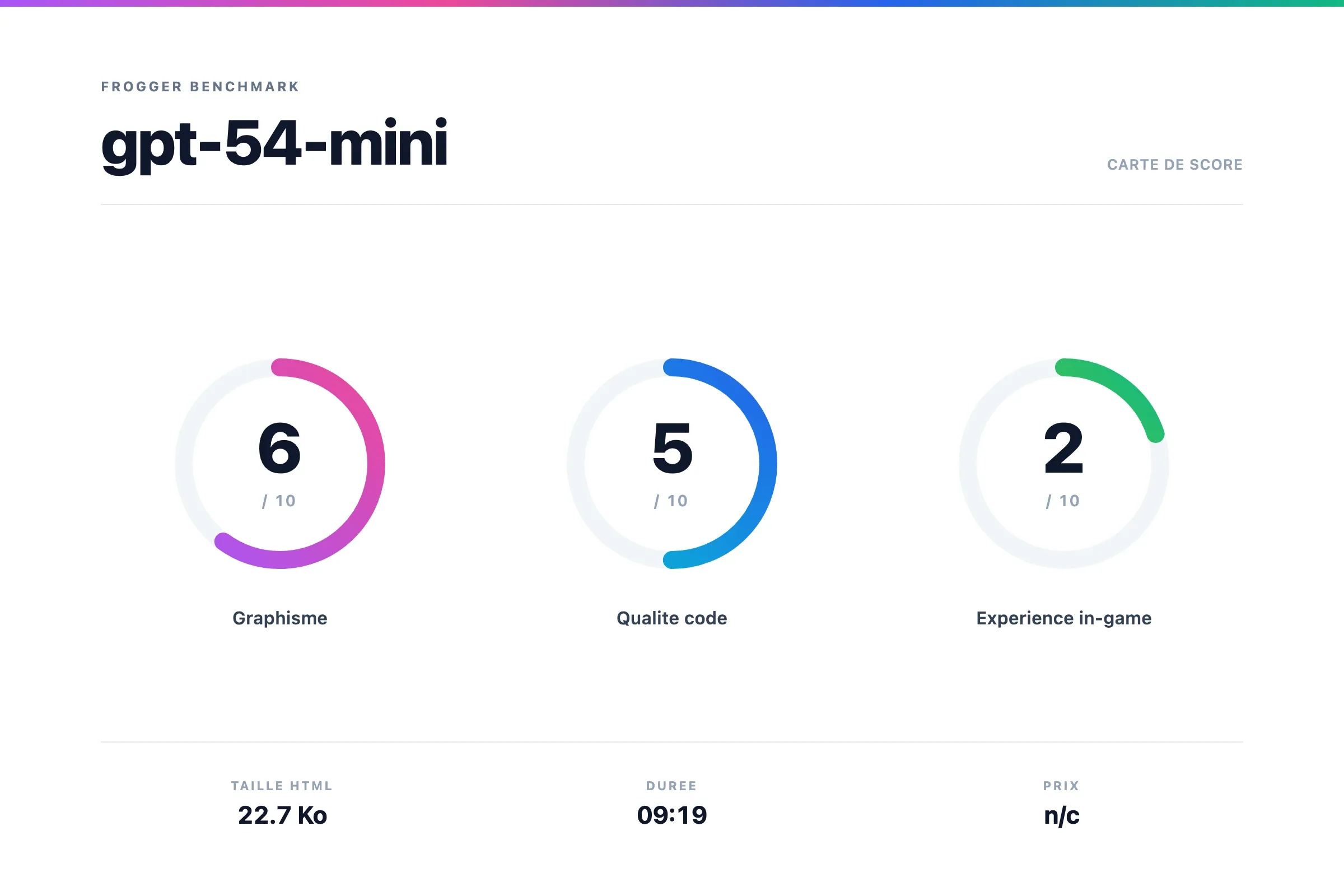
Verdict GPT 5.4 Mini
Déception, dès qu'on bouge notre crapaud tout s'arrête, ça freeze. L'animation se lance mais ça s'arrête quand on essaye d'y jouer. Le résultat est donc inexploitable.
GPT 5.4 Nano
Version encore plus low cost de GPT 5.4, mais qui sait... On peut avoir des surprises. 😂
Résultat
Scores
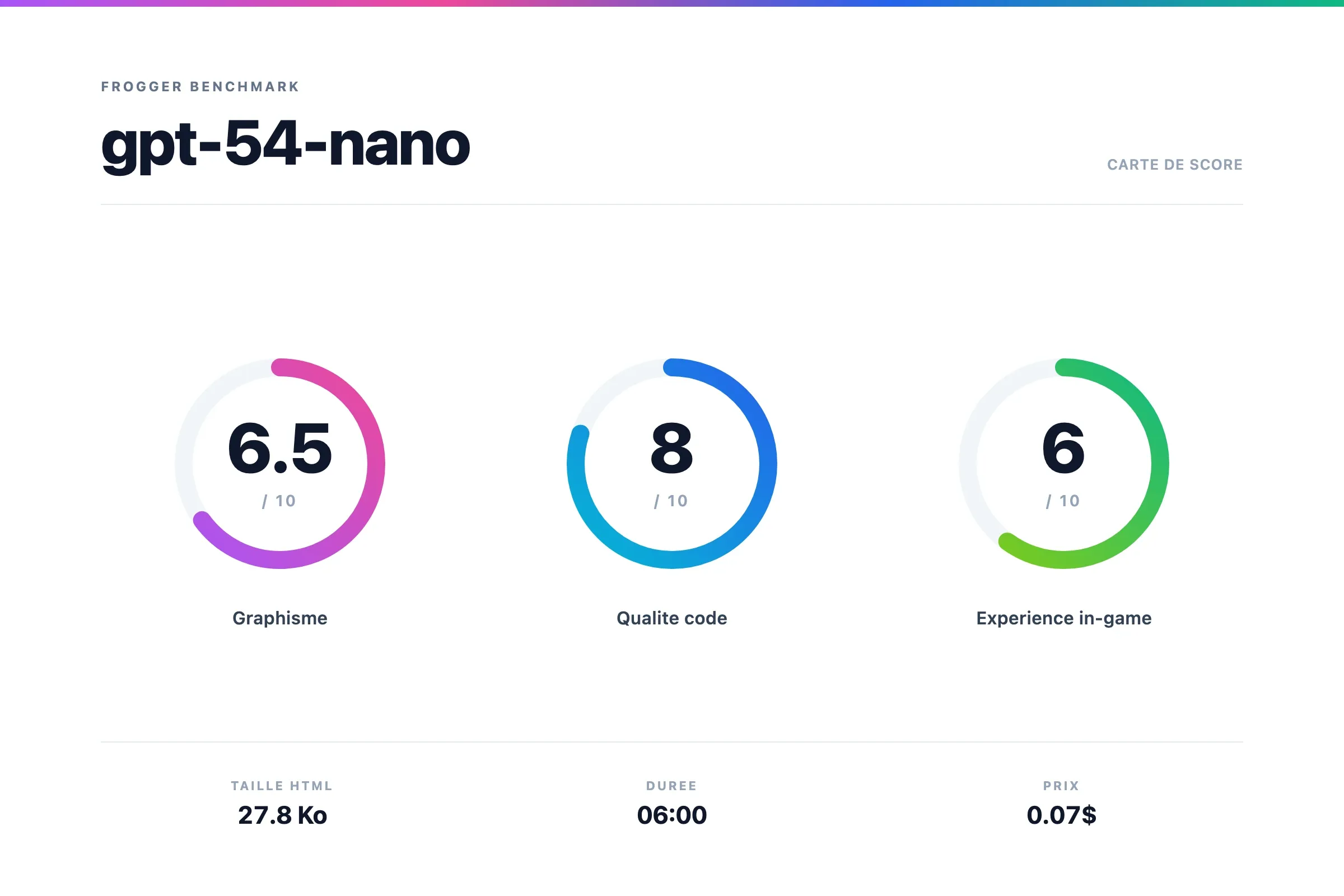
Verdict GPT 5.4 Nano
Incroyable, ça marche ! Il fait mieux que son "grand frère" pour moins cher.
GPT 5.5
Le GPT (presque) ultime, car il y a le GPT Pro après mais qui est hors de prix (et d'API aussi).
Résultat
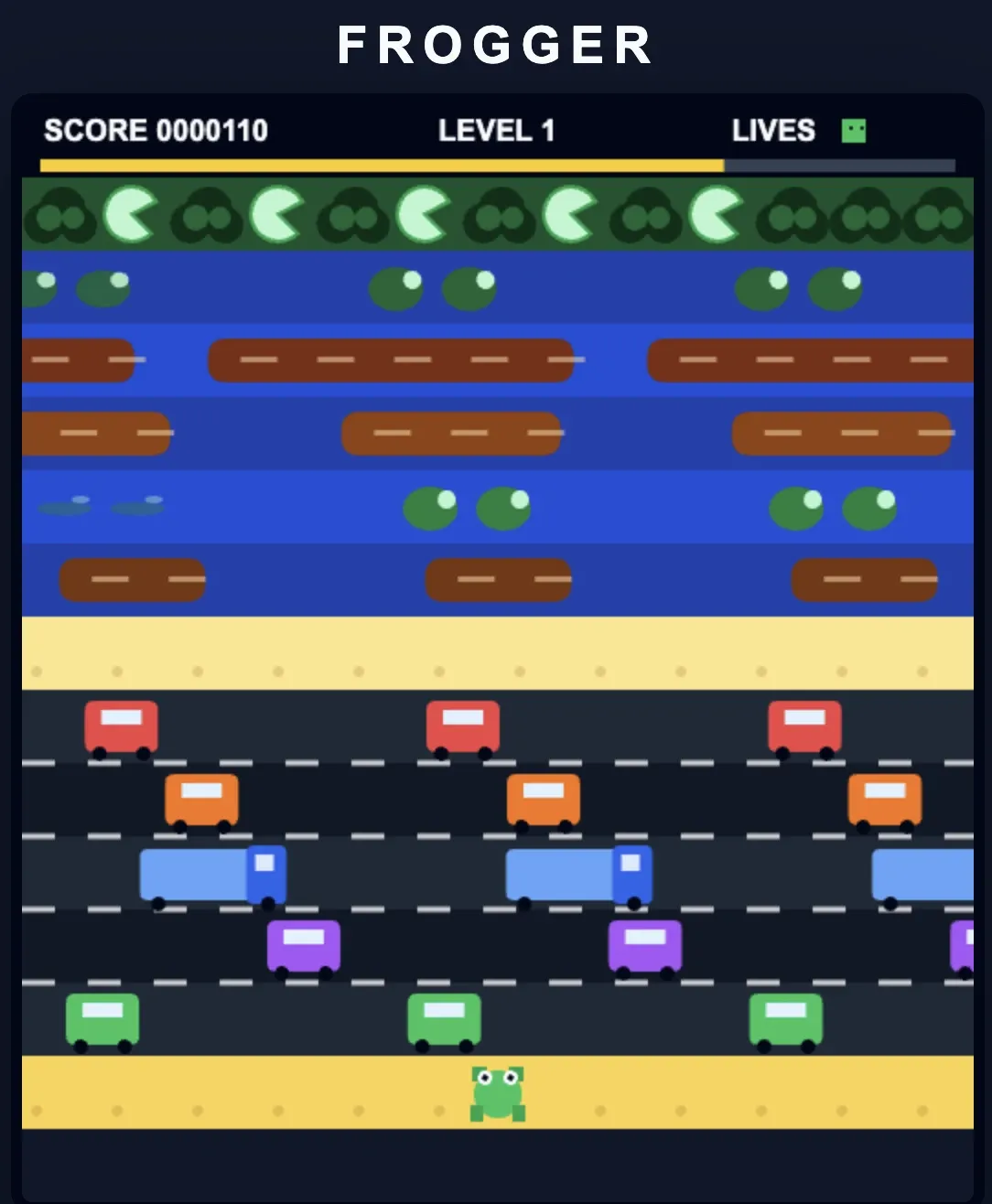
Scores
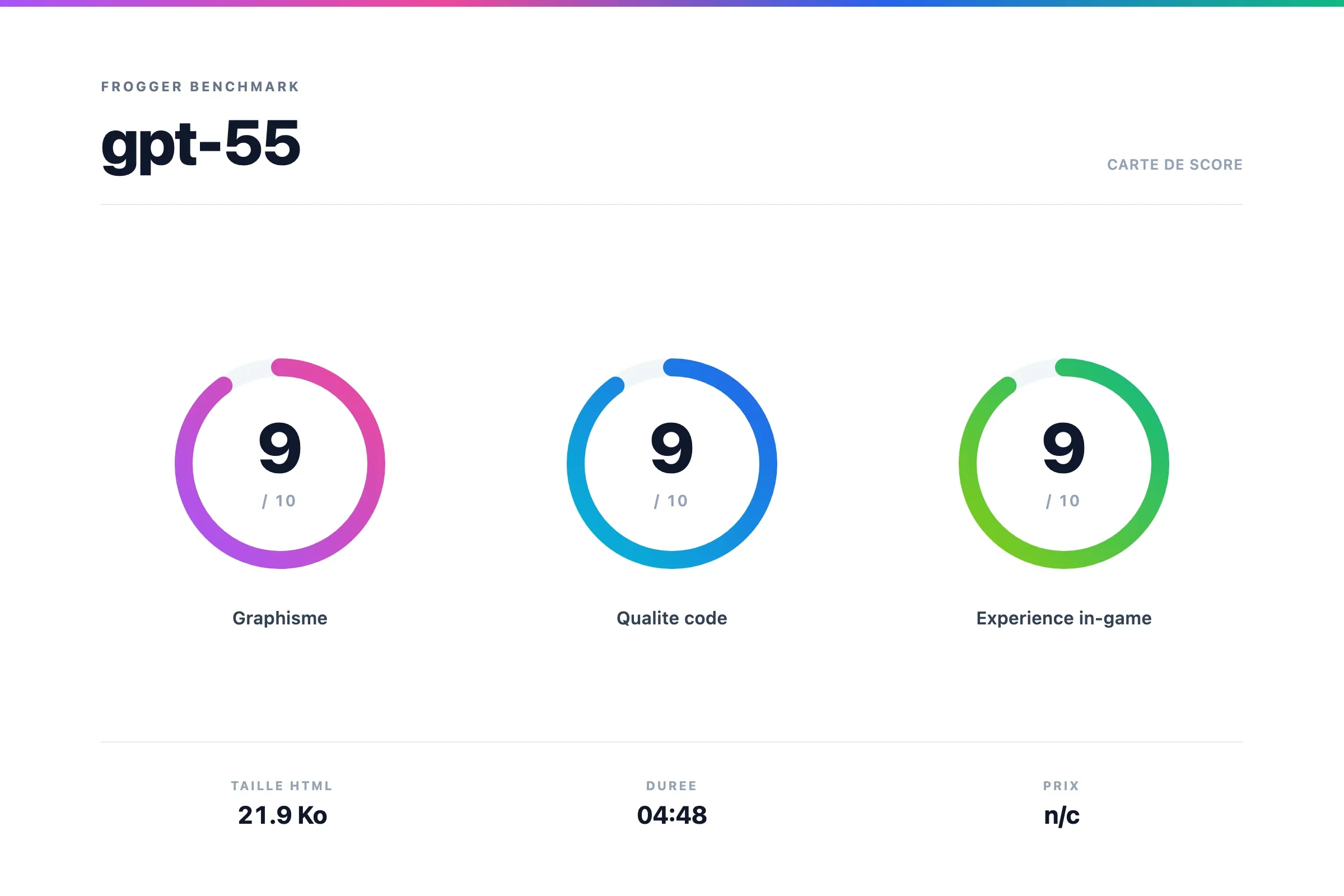
Verdict GPT 5.5
Wow, je pense que ça se voit qu'on est sur du haut de gamme. Le résultat est tout simplement BLUFFANT !
Kimi K2.6
Model chinois de Moonshot AI qui est pas mal plébiscité par les utilisateurs.
Résultat
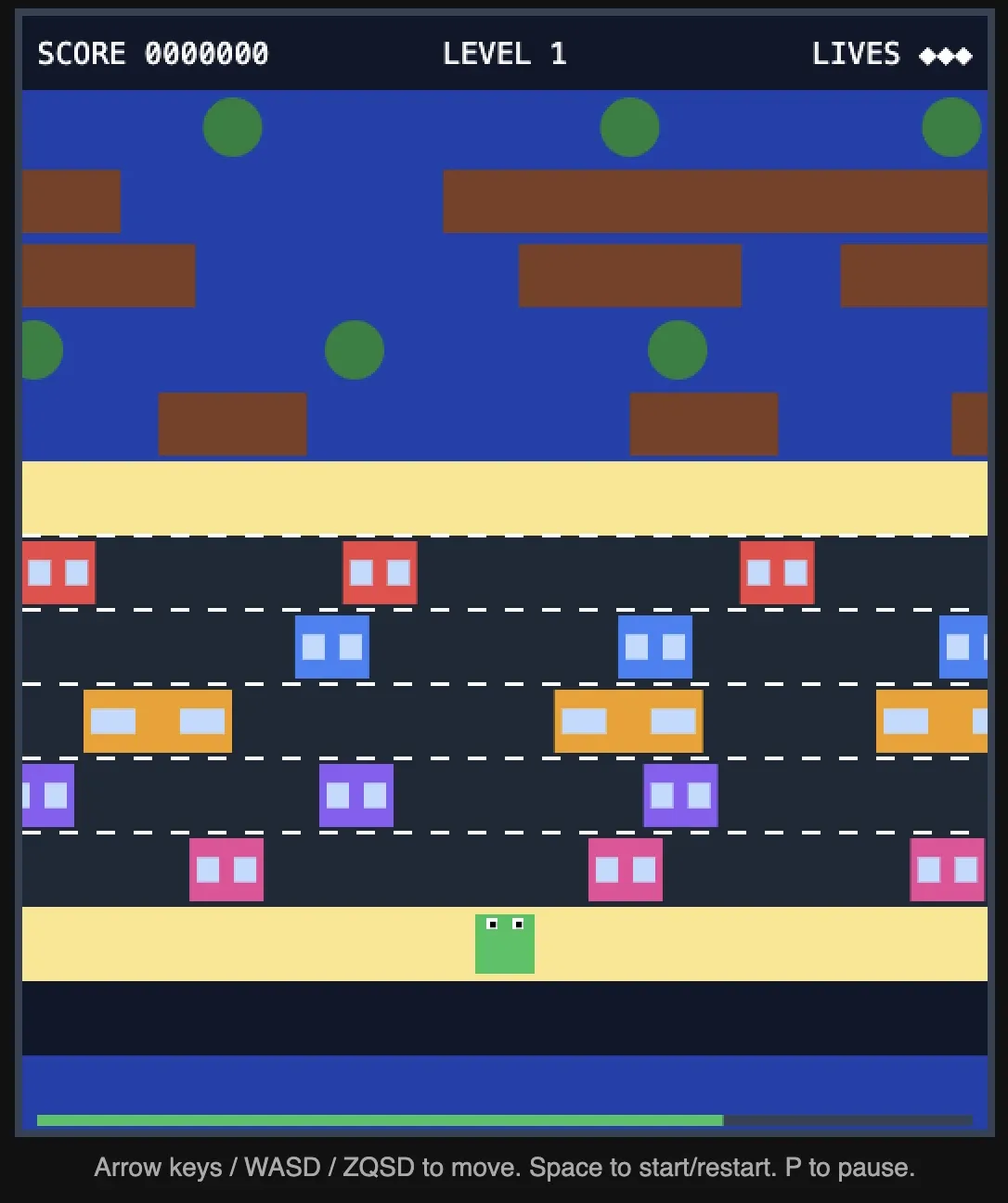
Scores
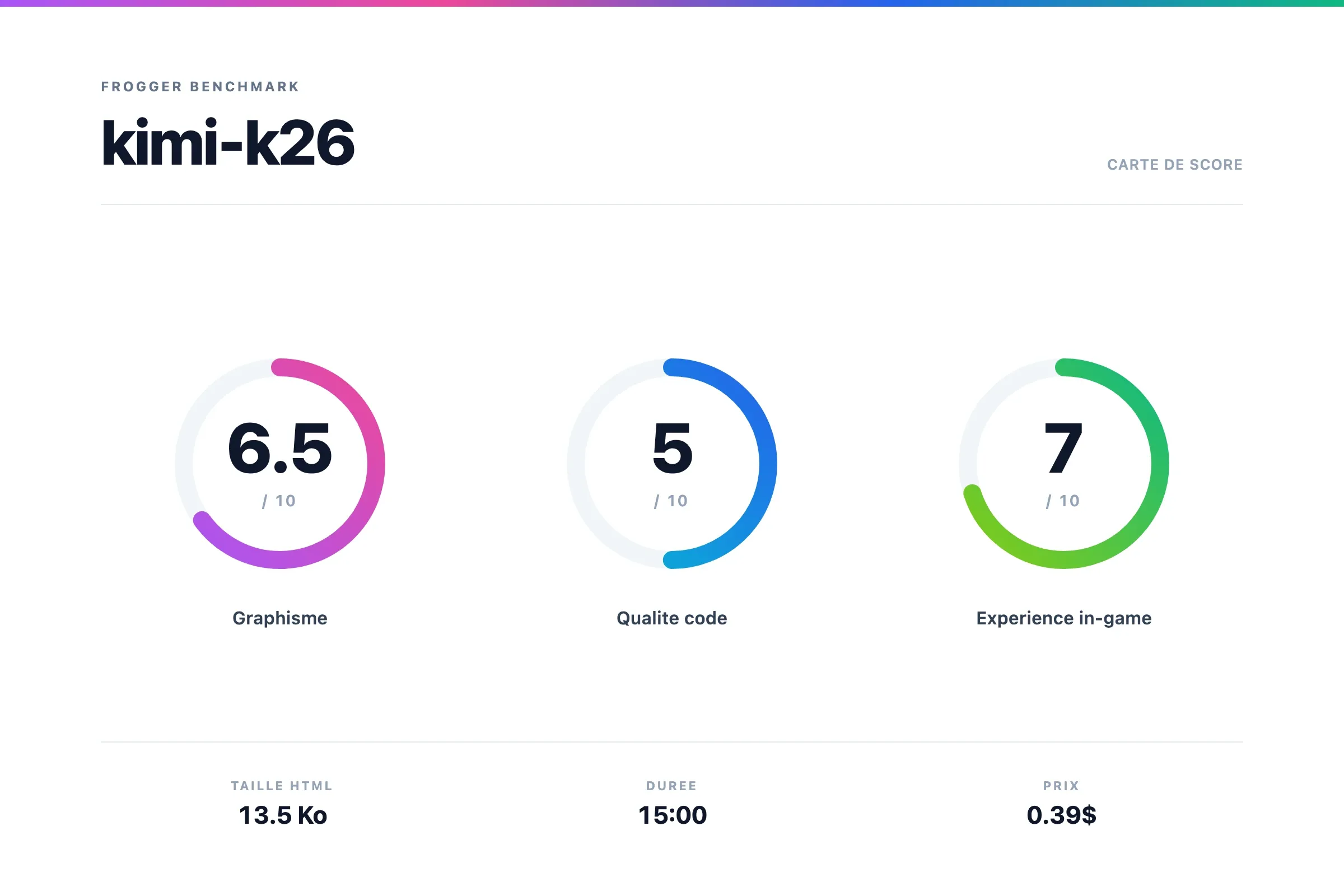
Verdict Kimi K2.6
Ce n'est pas le plus beau en terme de rendu mais ça marche bien, je me suis amusé.
Mimo v2.5 Pro
Model de Xiaomi qui est open source et pas mauvais.
Résultat

Scores
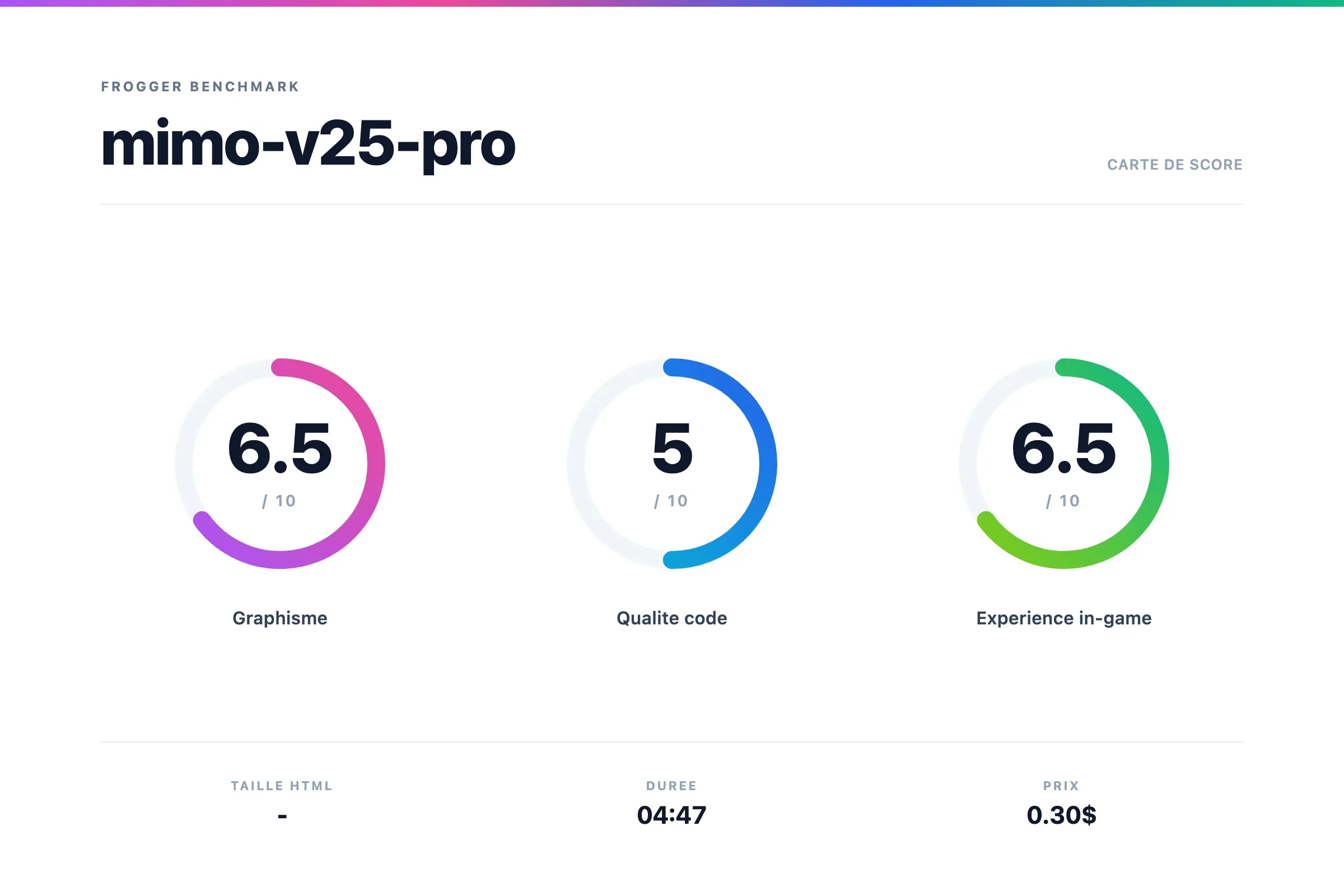
Verdict Mimo v2.5 Pro
Le résultat n'est pas mauvais, ça marche bien. Même si on peut constater un petit problème de collision parfois.
Minimax M2.7
Model open source qui est très apprécié dans la communauté open source et en Chine.
Résultat
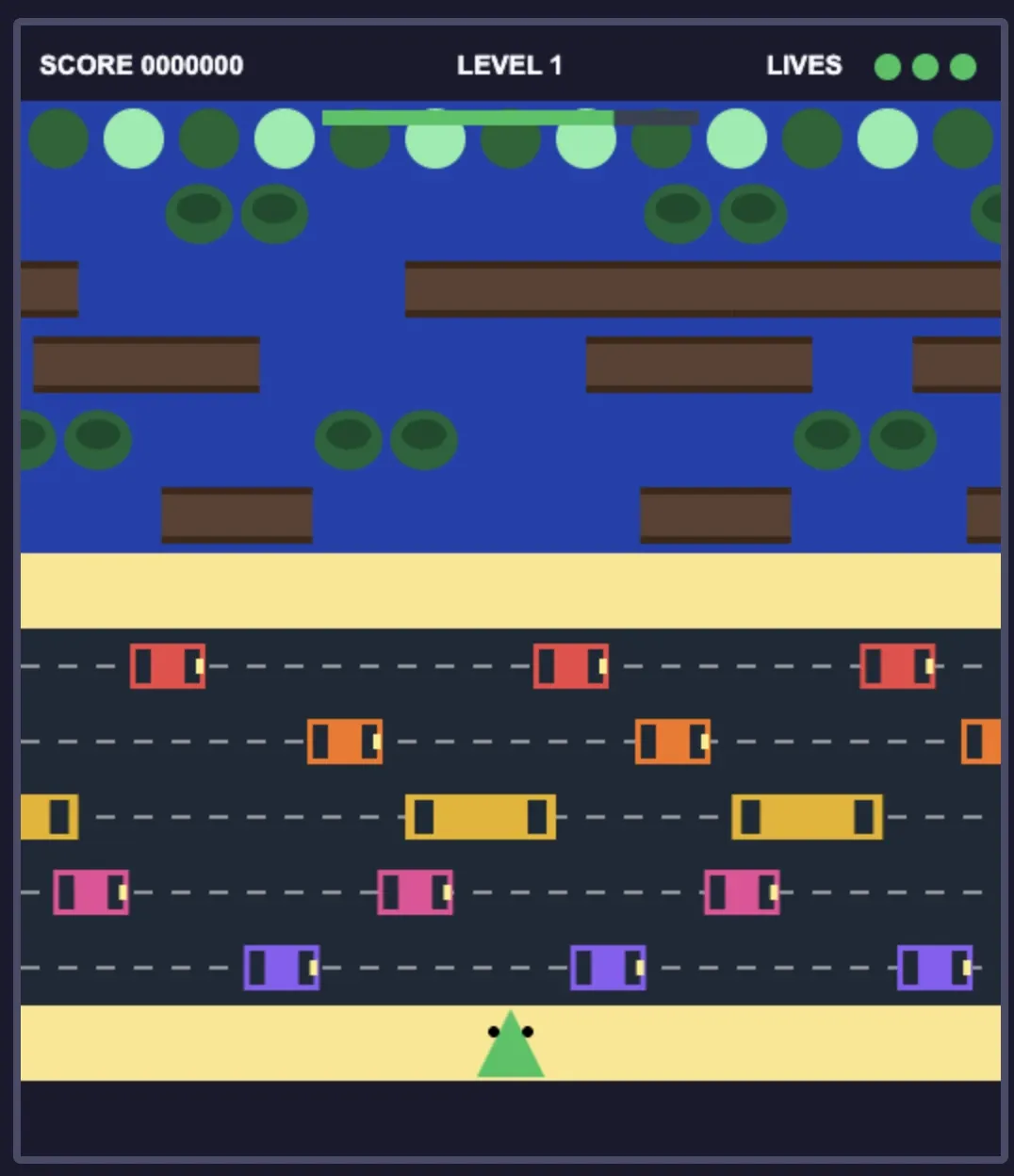
Scores
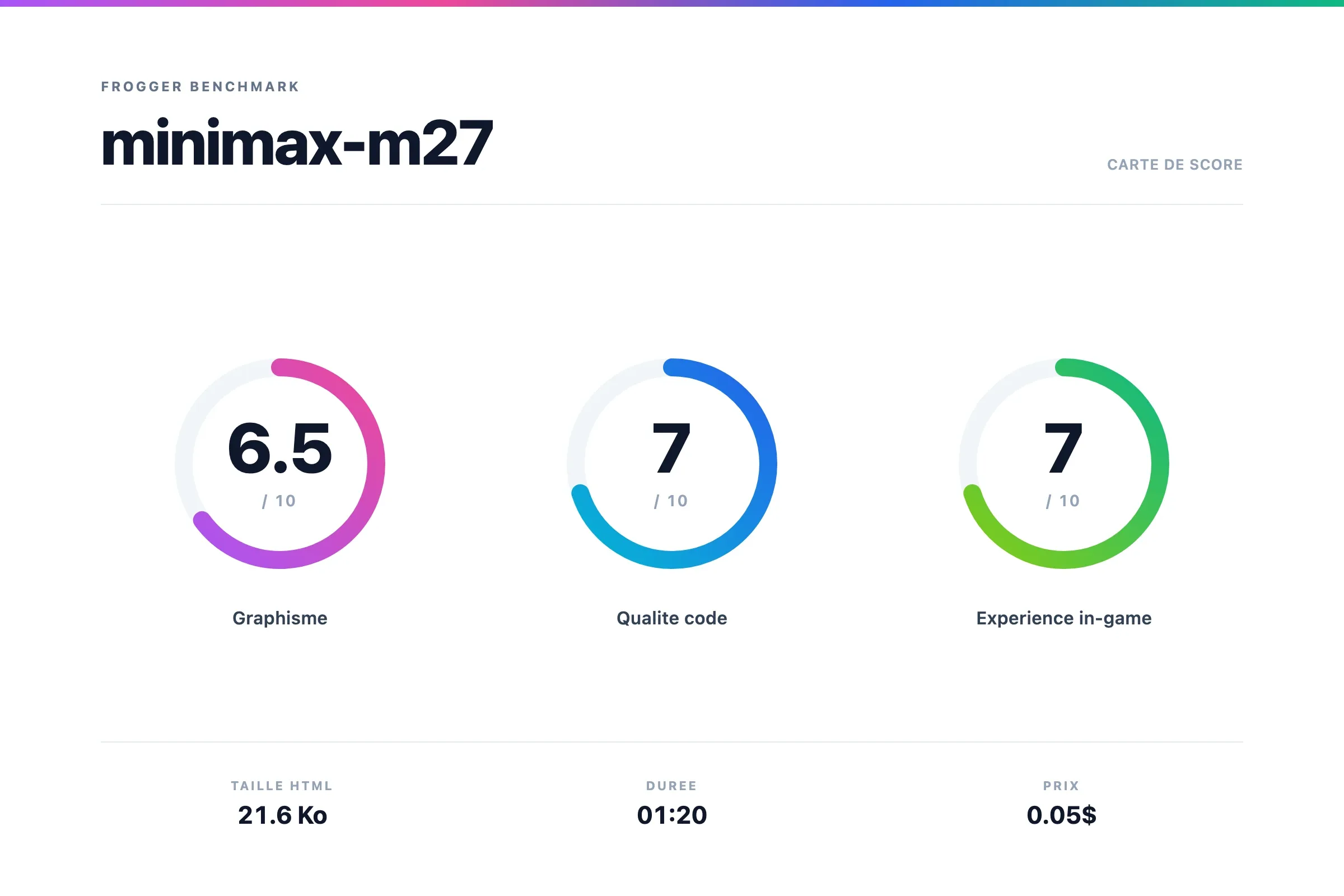
Verdict Minimax M2.7
C'est pas le plus beau graphiquement, mais le résultat est fun.
Opus 4.7
Flagship grand public d'Anthropic. On ne présente plus Claude.
Résultat
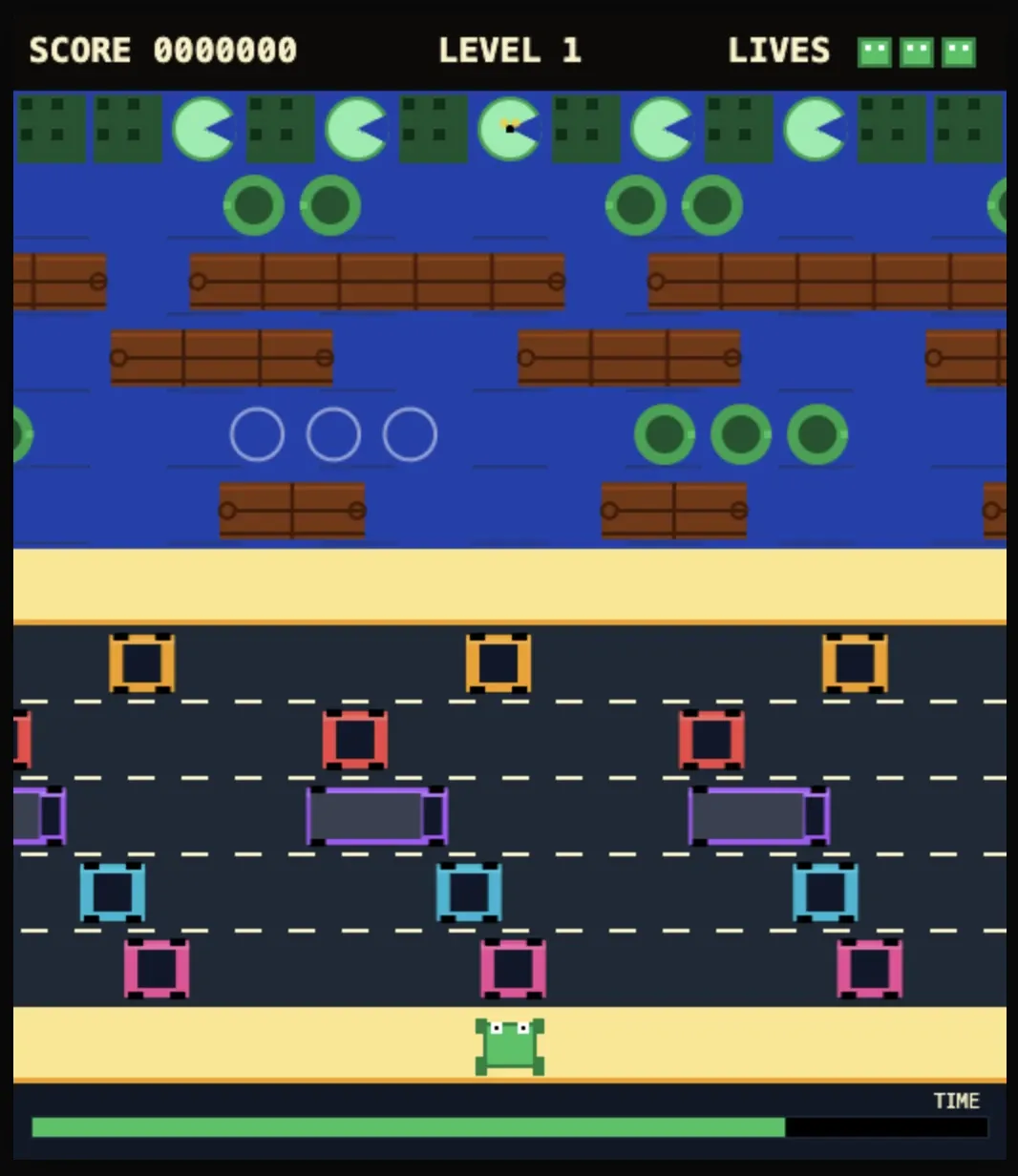
Scores
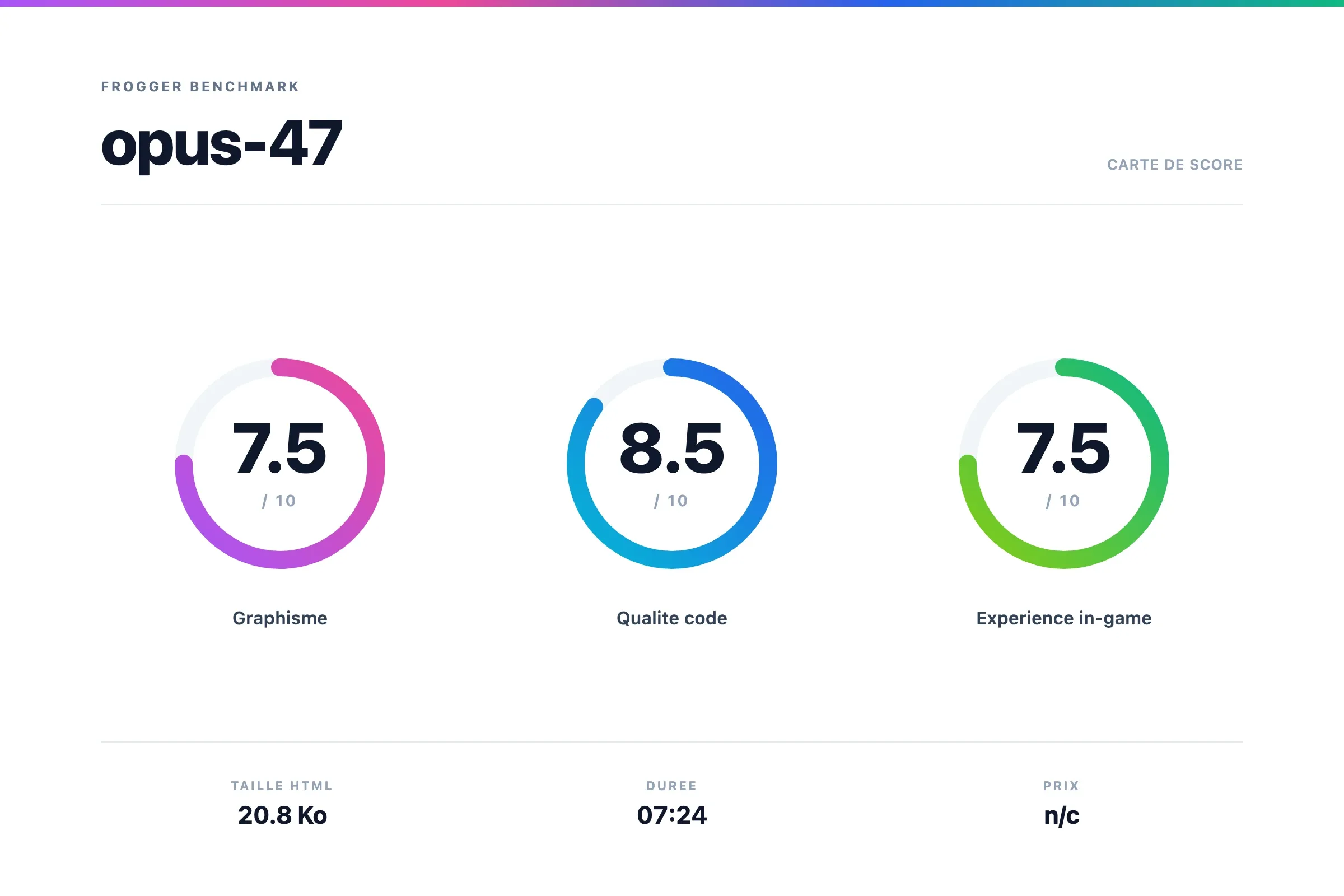
Verdict Opus 4.7
Bizarrement je suis un peu déçu pour la partie graphique mais j'ai beaucoup aimé le gameplay.
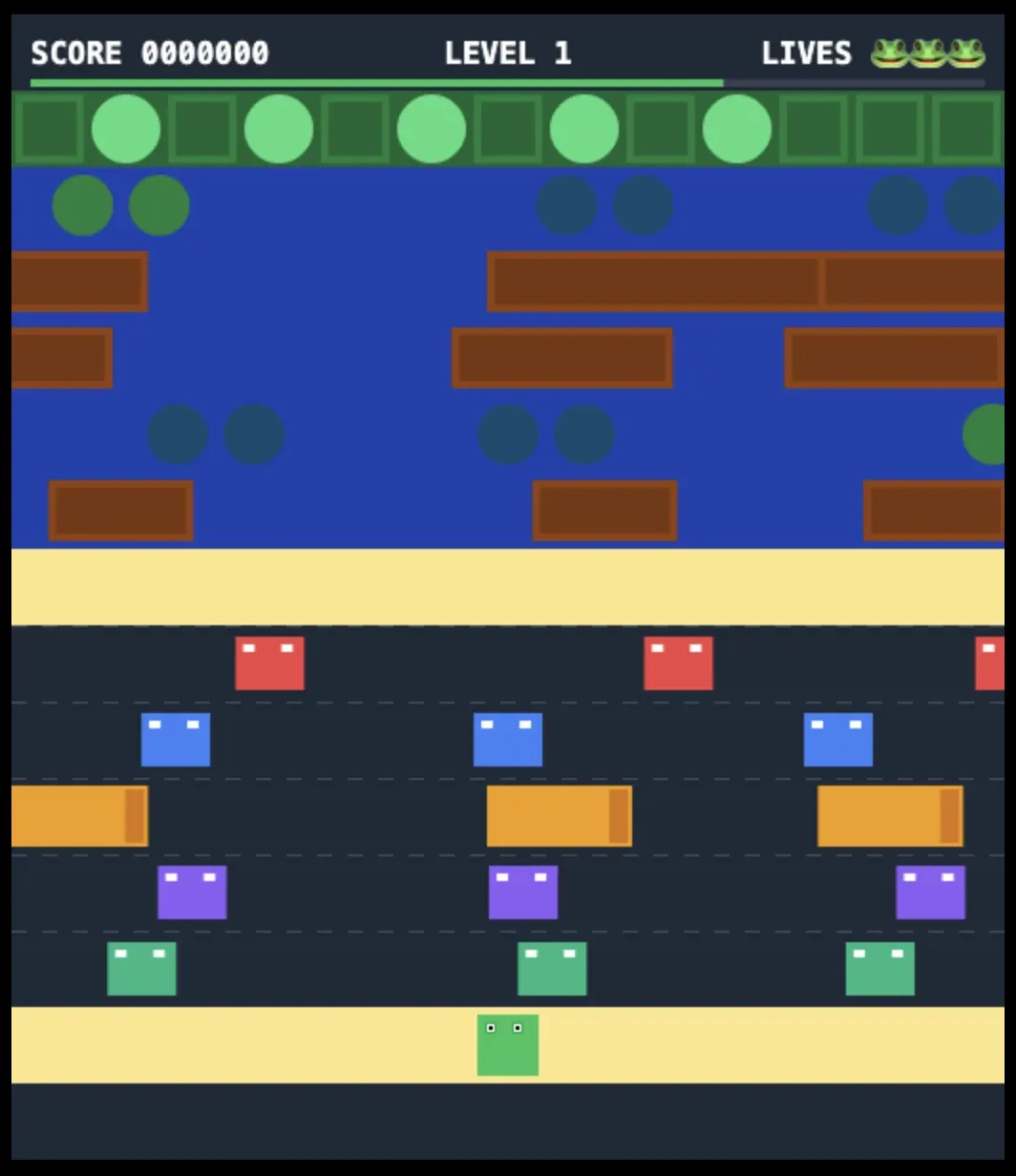
Qwen 3.6 Max
Model d'Alibaba dans sa version Max qui, je crois, est propriétaire comparé aux déclinaisons quantizées.
Résultat
Scores
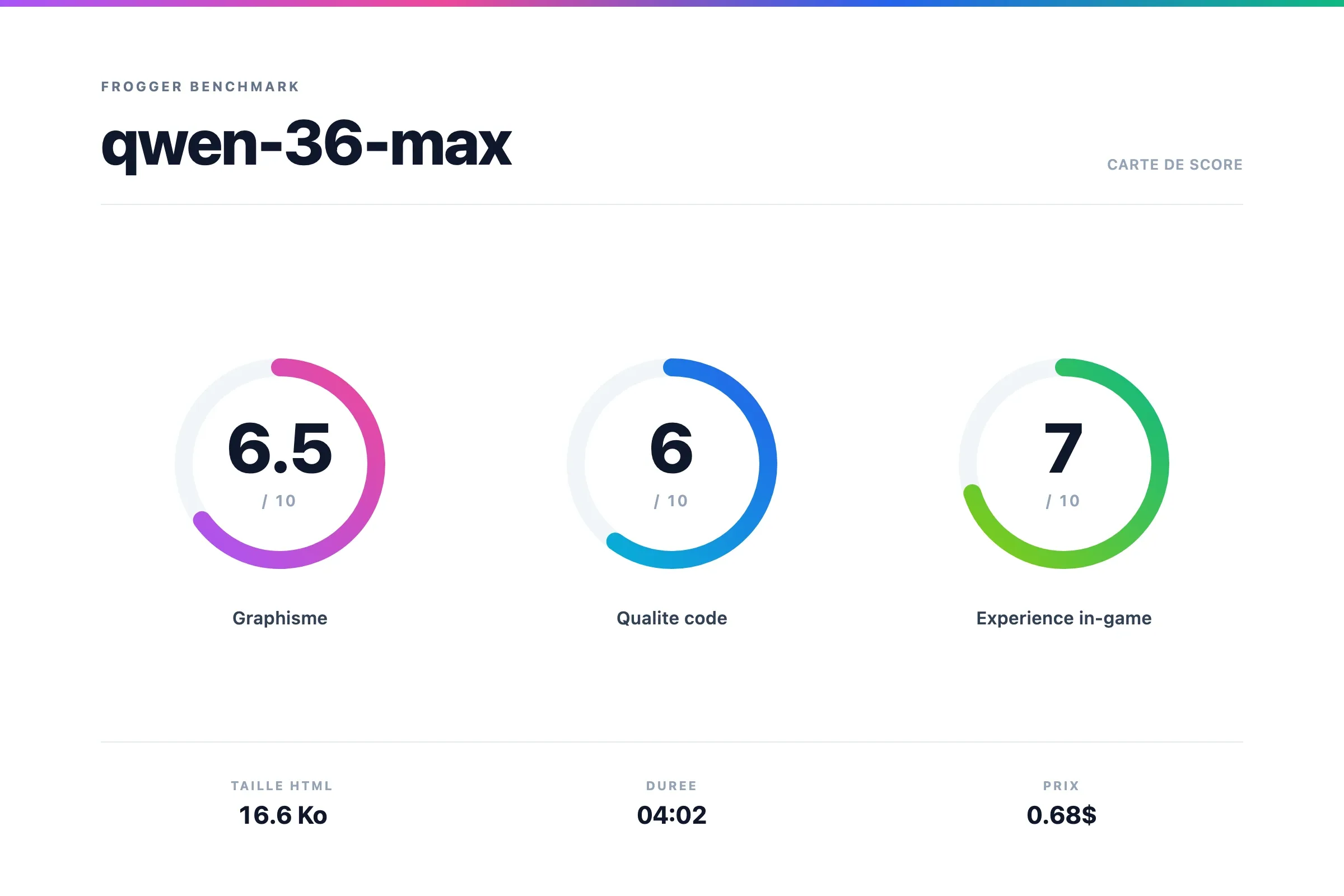
Verdict Qwen 3.6 Max
C'est pas le meilleur rendu graphique mais ça marche plutôt bien.
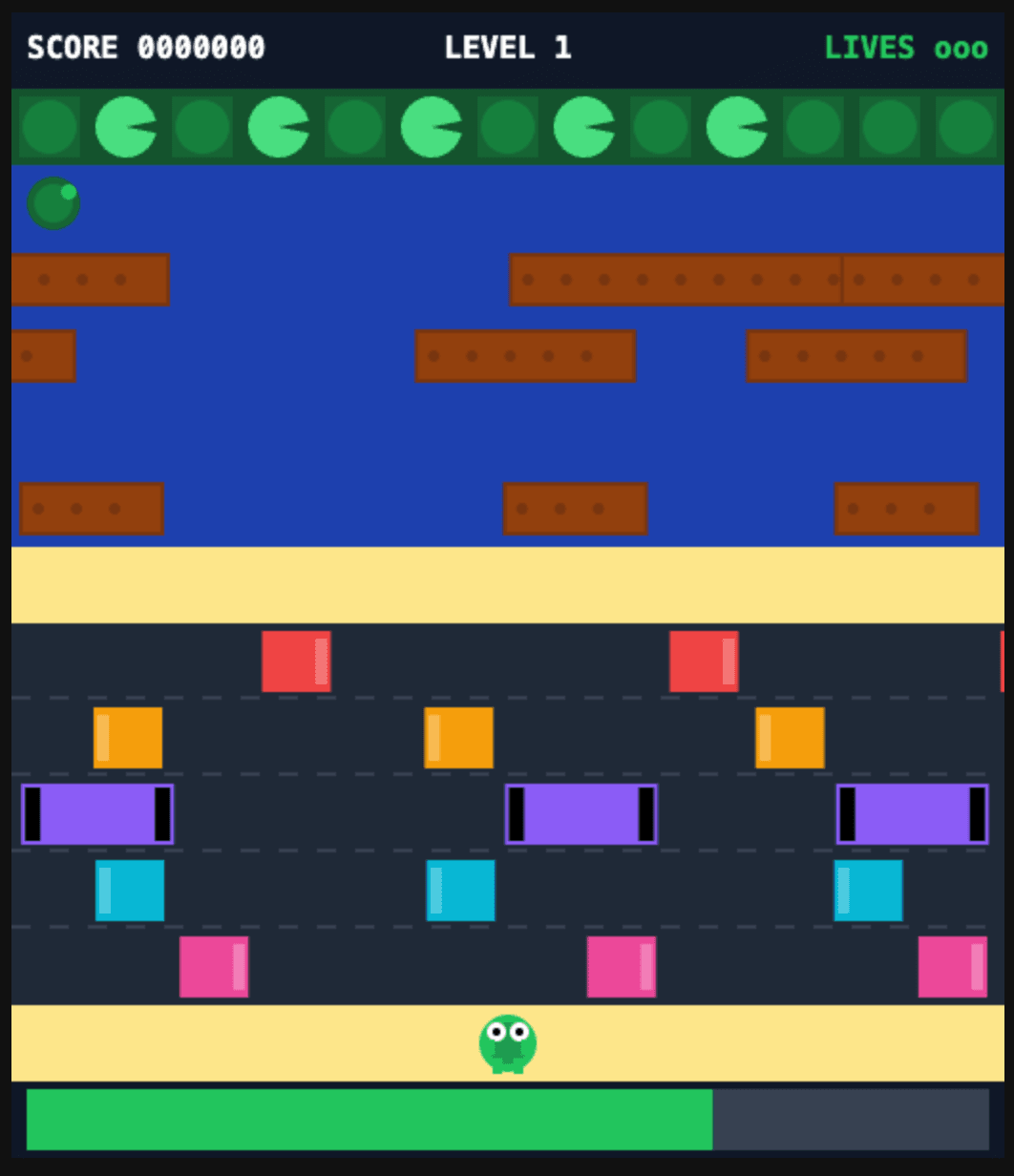
Qwen 3.7 Max
J'ajoute la dernière version de Qwen qui est désormais disponible sur OpenRouter.
Résultat
Scores
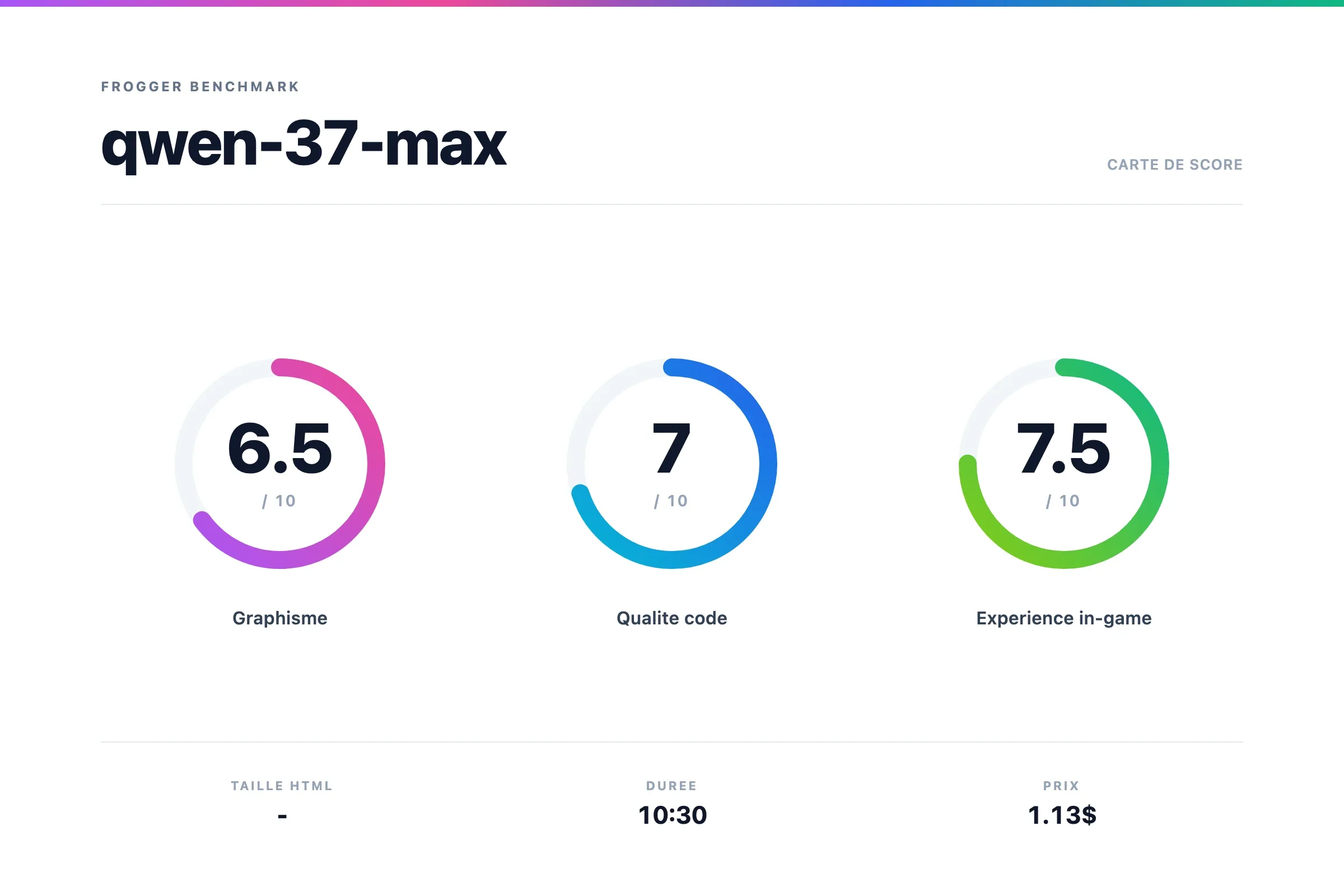
Verdict Qwen 3.7 Max
Toujours pas fou au niveau graphique, mais très fluide dans le gameplay. On constate aussi des améliorations dans le code.
Sonnet 4.6
Model grand public de Claude qu'on ne présente plus.
Résultat

Scores
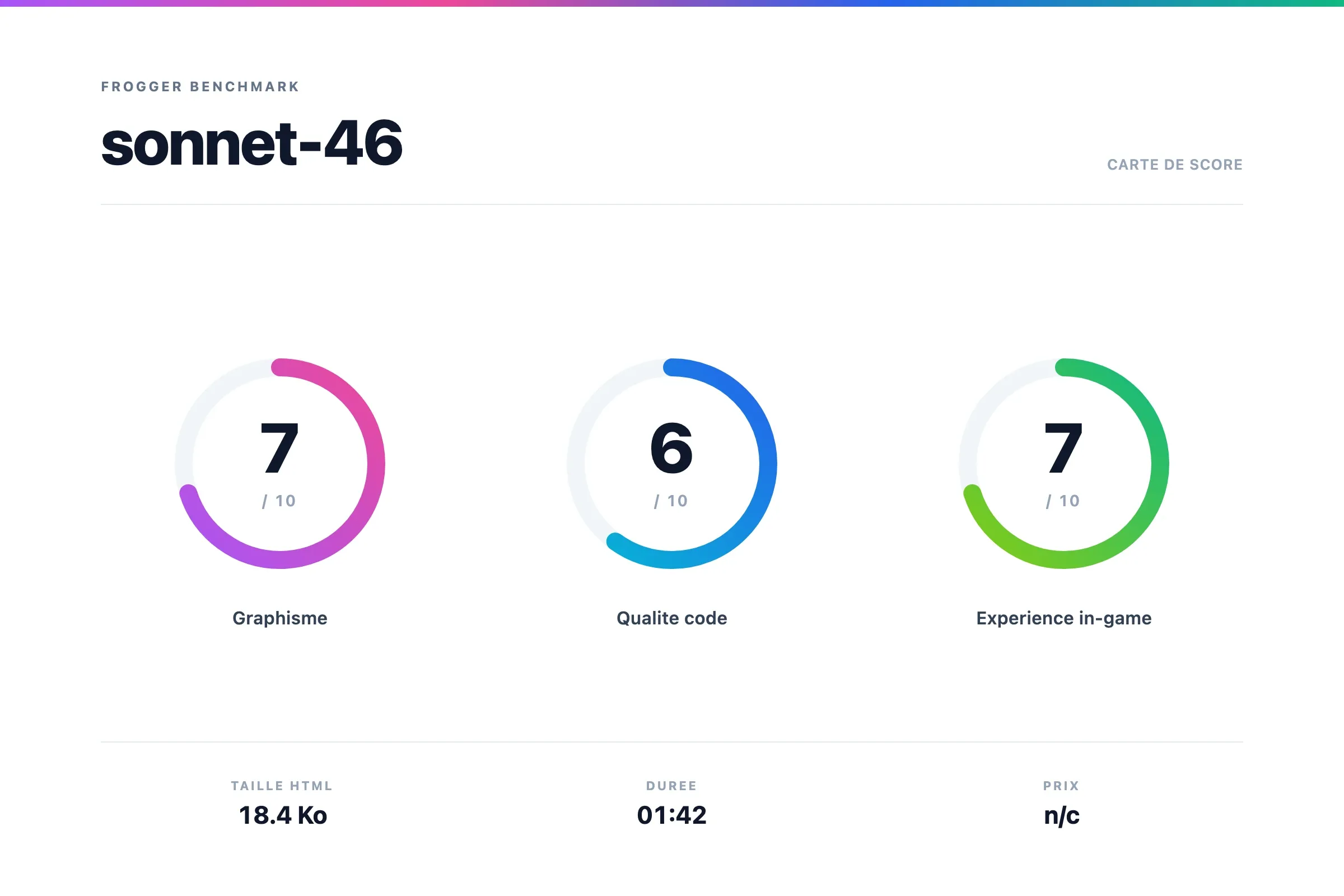
Verdict Sonnet 4.6
Sonnet 4.6 fonctione bien, il fait son job. Le rendu est pas mal et le gameplay est bon.
Bilan de ce benchmark
Après des heures de test, de standardisation etc... J'arrive à cette conclusion:
De manière générale, il y a peu d'écart entre les models.
Certains se vautrent lamentablement comme Gemini, alors qu'ils ne devraient pas.
D'autres sont moyens (quasiment tous en fait).
Mais dans tout ça, on a GPT 5.5 qui nous fait quelque chose d'incroyable pour son pesant de Louis d'or (j'exagère, il n'est pas si cher) 🤣.
Et on a un Deepseek v4 Pro qui fait quelque chose de pas mal du tout pour un prix ridicule 🤔.
Donc, oui, il y a de bons models aujourd'hui en 2026, mais il y a encore de mauvais prix.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.