Comment j'ai optimisé Strapi pour mon blog

J'ai accéléré mon site avec du cache Redis, en me servant de strapi comme CMS Headless. Je vous explique tout ici.
Utiliser les lifecycle de Strapi.js
Dernièrement je vous disais j'ai migré le blog depuis un projet custom Node.js Express & Handlebars vers un Next.js + Strapi TS-beta, et je ne regrette pas du tout. Cela m'a permis d'accélérer le processus développement au maximum. Au lieu de partir de 0 et devoir créer chaque brique, je suis parti de Strapi qui faisait tout le travaille de persistence et les routes API pour moi. J'estime que j'ai gagné 40% à 50% du temps de développement en procédant de la sorte.
Mise en place du caching avec Strapi
J'ai continué à améliorer cet outil avec une gestion de cache Redis qui permet de charger les données beaucoup plus rapidement du back au front.
Pour vous rafraîchir la mémoire je vous mets le lien de ma vidéo sur le caching ici .
J'ai mis en place des clés de caches en me basant sur les endpoints. En n'oubliant pas d'ajouter un pattern commun afin de pouvoir effectuer des actions groupés sur les clés de cache.
Lors de chaque Lecture, je vérifie d'abord l'existence des données dans le cache, et si Redis n'a pas de données, on va écrire le cache sans TTL. Etant donné que nous accédons à une seule et unique base dont le seul accès en écriture est Strapi, on respecte la règle qui nous permet de contrôler notre cycle de vie du cache.
En lecture :
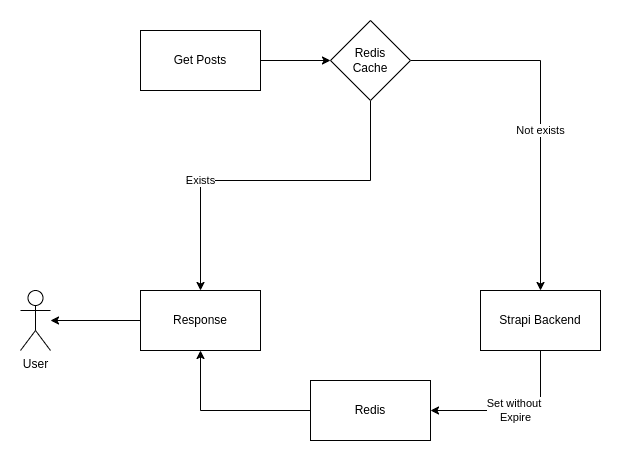
On récupère les données depuis le cache ou on écrit le cache sans limite de durée.
En écriture :
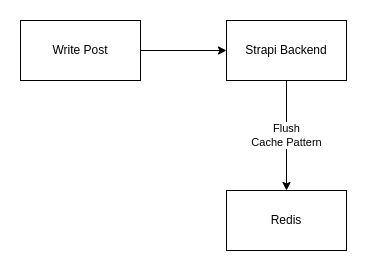
On en profite pour flusher totalement le cache via un pattern afin de récupérer de nouveau les données à jour. Autrement dit, je suis en mesure de garder le cache jusqu'à ce qu'un article soit modifié, supprimé ou qu'un nouvel article soit créé.
Cette simple optimisation me permet de charger mon contenu très rapidement, et éviter de flooder mon serveur Strapi en cas de requête répétée.
FAQ
Est-ce que cette approche fonctionne uniquement avec Strapi ou peut-on l'adapter à d'autres CMS ?
Le principe du cache Redis basé sur les endpoints et invalidé via un pattern est générique. Il peut s'adapter à tout CMS headless ou API REST, à condition de contrôler les points d'entrée en écriture pour savoir quand vider le cache.
Pourquoi ne pas utiliser de TTL sur les entrées Redis ?
Parce que Strapi est le seul à écrire en base, il est possible de savoir exactement quand les données changent. Sans TTL, le cache reste valide indéfiniment jusqu'à une modification réelle, ce qui évite des expirations inutiles et des appels superflus au serveur.
Comment le cache est-il invalidé quand on publie ou modifie un article ?
Grâce aux lifecycles de Strapi, chaque opération d'écriture déclenche un flush ciblé du cache via un pattern commun aux clés concernées. Toutes les entrées liées sont supprimées d'un coup, forçant le rechargement des données fraîches à la prochaine lecture.
Est-ce que cette optimisation a un impact mesurable sur les performances ?
L'auteur l'utilise pour éviter de saturer le serveur Strapi lors de requêtes répétées et pour accélérer le chargement du contenu côté front. L'impact est surtout visible en cas de trafic récurrent sur les mêmes pages.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.
Poursuivre la lecture

