
Dernièrement je voulais tester quelque chose:
Faire tourner un modèle de code en local avec l'interface de Claude Code pour manipuler les fichiers.
J'ai donc opté pour Free Claude Code un projet open source qui vous permet de faire un bridge entre claude code et vos LLM locaux (LM Studio ou Llama.cpp) ou distant sur Open Router ou Nvidia NIM.
Pourquoi c'est intéressant de faire tourner ses modèles de code en local ?
Sachez que le mode de l'Open Source innove et avance à grand pas. Bien qu'on en parle peu et occulté par la communication écrasante d'Anthropic, Google ou OpenAI. Les modèles Open Sources comme Mistral qui est français ou encore Deepseek, Qwen, GLM chez les chinois ne sont pas en reste.
Et on ne le dira jamais assez mais pour le moment les géants de l'IA ne sont pas rentables (à part Google capable de couvrir ses pertes avec ses autres marchés). Donc nous ne sommes pas à l'abri d'une forte inflation prochaine. D'ailleurs Anthropic a commencé un A/B testing sur le fait de désactiver Claude code sur certains compte Pro pour vous obliger à prendre au minimum Claude Max à 90€.
Je pense que prendre l'habitude d'être indépendant au niveau des modèles de code, c'est prévoir une inflation prochaine rendant les meilleurs modèles très élitistes. De même, avec la progression de l'Open Source, on pourra lever le pied sur les modèles commerciaux. En sachant qu'ils seront non seulement en accès libre mais également compatible avec les machines modestes.
D'ailleurs avec les dernières optimisations en matière de MoE (Mixture of Expert), le modèle a tendance à activer le nombre de paramètres nécessaires pour tourner au lieu de tout solliciter à chaque fois. Et Qwen 3.6 35B A3B d'Alibaba en est un bon exemple, de sont côté Google dispose de Gemma en tant que modèle Open Source sorti dernièrement dans sa version 4.
Qwen 3.6 35B A3B, c'est quoi ce truc ?
En fait, c'est un modèle de 35 milliards de paramètres qui n'active que 3 milliards de paramètres à chaque fois grâce au MoE.
D'ailleurs, il obtient de très bons résultats en benchmark comparé au modèle de Google qui n'est pas en reste côté performance:
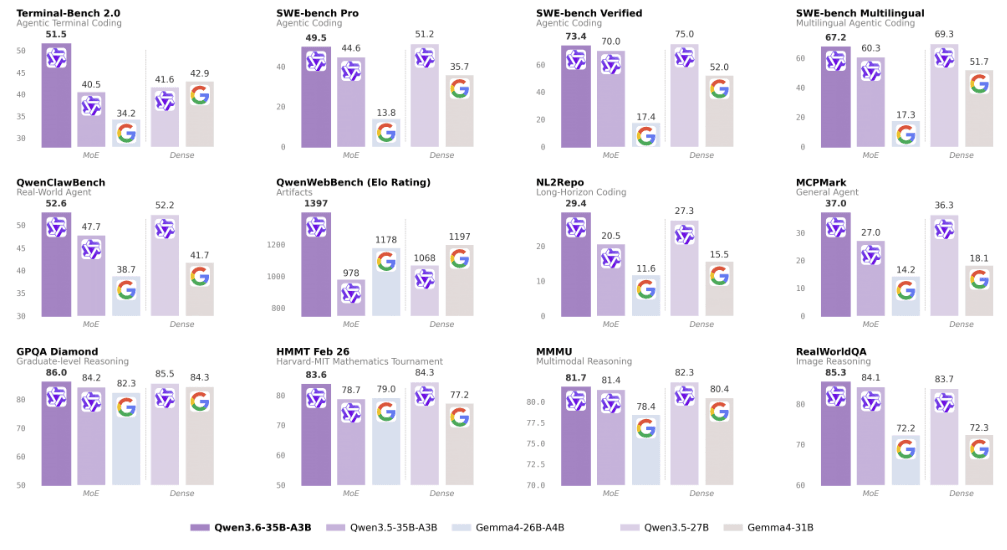
Dans certains tests il rivalise même avec Claude Sonnet 4.5 qui n'est certes pas le meilleurs modèle, mais pour de l'Open Source, c'est assez incroyable.
Les tests
Premièrement, je me sers de LM Studio pour télécharger facilement les modèles et les exposer, pour la partie Free Claude Code, j'ai suivi leur Readme à la lettre.
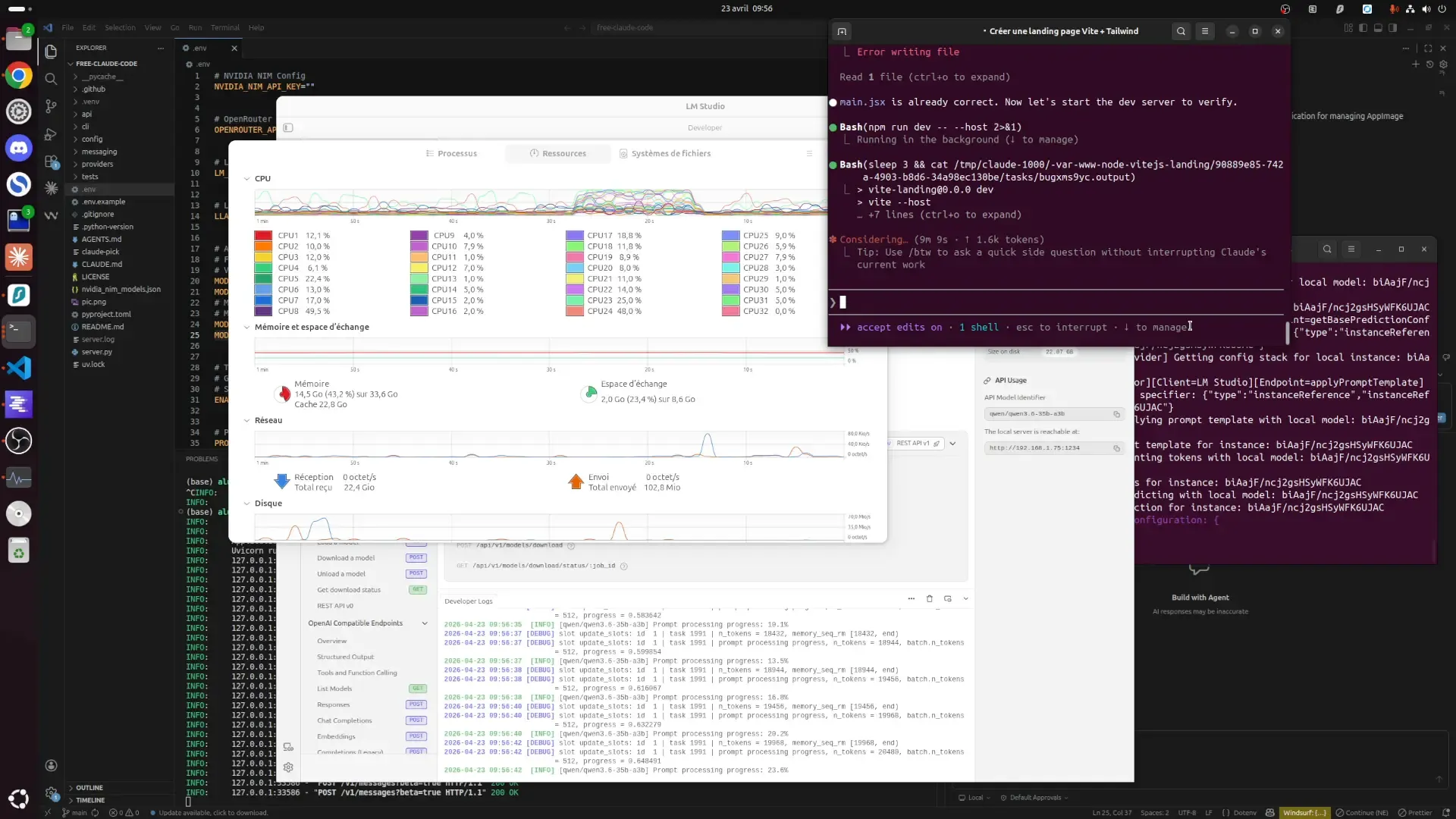
J'ai utilisé Qwen 3.6 35B A3B sur un contexte de 100k token avec un offload par défaut. Le offload c'est le fait d'équilibrer RAM/VRAM, en gros plus on offload, plus on sollicite le GPU pleinement. Mais comme le modèle fait 35B soit 22GB et que mon GPU n'a que 16GB de VRAM (RTX 5060 Ti), je ne peux pas offloader à 100%.
Donc je vais décharger parfois les paramètres sur la RAM et les reprendre en fonction du besoin... Ce n'est clairement pas la situation optimale.
Mais déjà on a un résultat, je demande un projet "Vite JS avec Tailwind qui affiche un Hello World".
10 minutes et 10 secondes plus tard, j'obtiens ceci:

Oui, 10 minutes pour seulement ça, et c'est déjà une prouesse car je vous le rappelle, ça tourne en local sur du matériel grand public.
Avec un GPU haut de gamme je suis persuadé qu'on peut faire bien mieux.
Second test
Je refais une tentative cette fois ci en augmentant le offload pour solliciter un peu plus mon GPU et réduire légèrement le contexte... Après tout, 100k token pour un Hello World, c'est un peu overkill.
Résultat en 9 minutes:

Donc je pense qu'il y a moyen d'optimiser, de tout tweaker pour obtenir de meilleurs résultats.
Dernier test avec GLM 4.7 Flash
J'ai fait un dernier test avec un modèle GLM 4.7 Flash 30B avec quantization (celui d'unsloth suggéré par Free Claude Code, il pèse 13GB). J'ai offloadé à 100% avec un contexte de 40K token.
Le résultat est mauvais, il n'a pas respecté mon instruction ViteJS et s'est contenté d'une page HTML qui affiche "Hello world" en haut à gauche.
Il aura pris 50 secondes pour le faire...

Bilan
Ce n'est pas parfait, ce n'est pas fou, mais c'est un premier pas important.
Il faut une première étape pour arriver à quelque chose de meilleur et je ne perds pas espoir qu'à terme, on ait des modèles locaux aussi performant que les modèles commerciaux.

