Les secrets du Harness pour le coding agentique

Deepseek v4 Pro avait décroché un 5/10 en qualité de code. En retravaillant le prompt et en testant deux harness différents, les résultats changent vraiment.
Dernièrement, je vous proposais un benchmark géant des models LLM.
Lors de ce benchmark, un de mes models favoris Deepseek v4 Pro avait obtenu un score de 5/10 en qualité de code. Ce qui n'est pas terrible en soi, mais ce n'est pas non plus irrattrapable.
Pour rappel, la qualité de code était évaluée sur différents critères:
- respect des best practices,
- usage de patterns,
- DRY,
- factorisation,
- code propre,
- nommage des vars,
- nommage des functions
Je pense que c'est la base pour faire du code scalable, rien de compliqué jusque là.
Constat
Une note de 5 sur 10 raconte une histoire sur comment le model s'y prend pour effectuer ses tâches.
Lorsque l'on ramène à la durée (plus de 11 minutes) certes pour un mode thinking high, ça veut dire qu'on a attendu longtemps pour quelque chose de qualité moyenne.
Sur les critères d'évaluations, il y a plusieurs points qui n'ont pas été respectés.
Je pense que le plus important c'était surtout que tout était envoyé dans une seule fonction.
Un bloc monolithique dans lequel il a tout mis.
Hypothèse
Vous savez, l'IA est comme un adolescant qui a encore besoin d'éducation.
Lorsque vous lui confiez une tâche, si le résultat n'est pas exactement comme vous voulez, il y a de fortes chances qu'en corrigeant ce que vous lui demandez:
- soit on se rapproche du résultat souhaité
- soit on obtient ce que vous avez en tête
C'est à dire qu'il est doté de capacité mais est forcément limité par votre vision qui, pour le moment, est dans votre tête.
Votre travail consiste à lui fournir au mieux les éléments permettant de comprendre votre besoin.
Donc, je me suis dit:
Okay. Je vais reprendre le prompt du projet et lui donner des éléments précis sur comment doit il fournir le code.
A aucun moment je lui dis exactement quoi faire du genre:
- fait une fonction XXXXX
- utilise une variable XXXXX de cette façon...
Non !
Je le laisse faire, mais je le cadre sur ce que j'attends de lui techniquement:
- quel pattern je veux qu'il utilise
- quel approche est interdite etc...
Puis, j'ai dressé 2 plans de tests:
- Je refais mon prompt mais j'ajoute toutes les guidelines pour le code et j'implémente avec Opencode
- Je refais mon prompt mais j'ajoute toutes les guidelines pour le code et j'implémente avec Claude code
Mon hypothèse:
What if, le harness contient plus de guidelines qu'il n'y parait ?
En gros, est-ce que Claude code, ajoute implicitement plusieurs règles de code de son côté, invisibles pour celui qui prompt ?
Résultats
Je relance le script de scoring sur le code, et voici les résultats:
- Deepseek v4 Pro + spec détaillée pour le code + Opencode = 7.5
- Deepseek v4 Pro + spec détaillée pour le code + Claude code = 7
Rendu Opencode
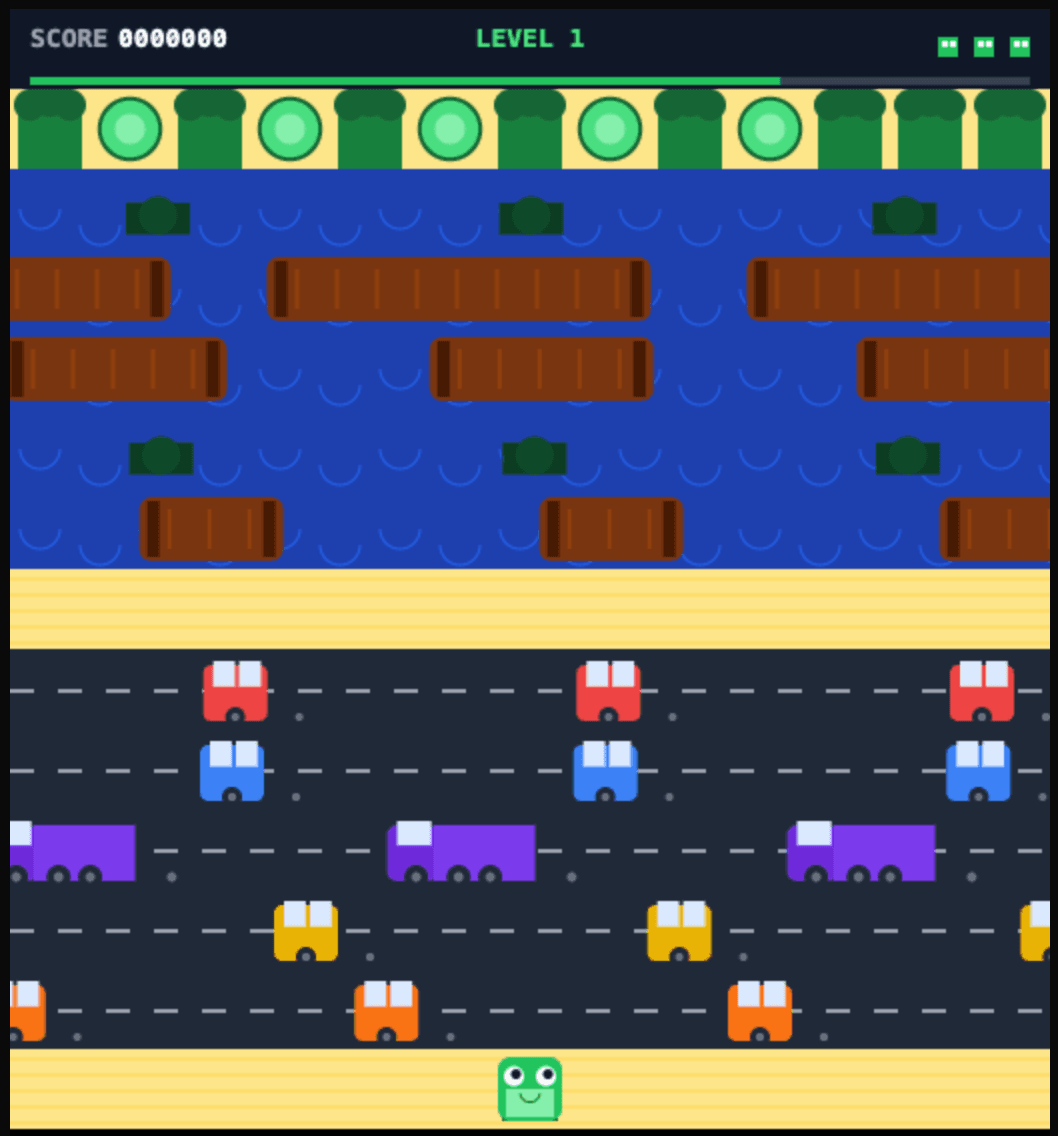
Rendu Claude Code

Pourquoi ?
Parce que Claude code a mixé quelques "var" en plus des "const/let" et ce n'est pas propre. De même il a généré un bug de calcul du chance per frame.
D'où l'avantage de la version Opencode là dessus, qui a suivi le prompt un peu plus à la lettre.
Je précise que ces résultats sont conditionnés à ce cas d'utilisation. J'imagine que si on évalue autre chose:
- faire un site web (HTML+ experience),
- faire un script bash (plus système)
Les résultats peuvent être différents.
Conclusion
Lorsqu'un agent vous fourni un résultat insatisfaisant, c'est le signe que vous devez retravailler votre prompt.
De plus, les harness joue un rôle dans le résultat, il y a probablement du pre-context invisible pour vous côté serveur, donc je vous recommande de faire des tests avec différents outils afin de comparer les résultats.
Pour ma part, c'est Opencode qui gagne cette fois-ci, mais il est fort probable que vous ayez des résultats différents.
FAQ
Comment améliorer concrètement la qualité du code produit par un LLM sans tout lui dicter ?
Il suffit d'enrichir le prompt avec des contraintes techniques précises : quel pattern utiliser, quelles approches sont interdites, quel style de nommage est attendu. Le modèle conserve sa liberté d'implémentation mais reste cadré sur ce qui compte pour vous.
Passer de 5/10 à 7,5/10, c'est vraiment uniquement grâce au prompt ?
En grande partie, oui. Le même modèle Deepseek v4 Pro a produit un code nettement mieux structuré simplement parce que les attentes étaient formulées explicitement, notamment pour éviter les blocs monolithiques.
Pourquoi Claude Code a-t-il obtenu un score légèrement inférieur à Opencode ici ?
Claude Code a mélangé des déclarations var avec const/let et a introduit un bug de calcul, ce qui a pénalisé son score. Opencode a suivi le prompt plus fidèlement sur ce cas précis.
Est-ce que le harness (l'outil d'exécution) influence vraiment le résultat final ?
Oui, les outils comme Claude Code ou Opencode ajoutent probablement du contexte côté serveur, invisible pour l'utilisateur. Ce pré-contexte peut orienter le comportement du modèle indépendamment de votre prompt.
Ces résultats s'appliquent-ils à tous les types de projets ?
Non, ils sont spécifiques à ce cas d'utilisation. Sur un projet web, un script bash ou une autre nature de tâche, les classements entre outils pourraient être complètement différents. Tester sur votre propre contexte reste indispensable.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.
Poursuivre la lecture

