Mon essai non concluant de GLM 5.2

Décompilation de Simpsons Hit & Run avec l'IA : GLM 5.2 mis à l'épreuve sur une codebase complexe. Résultat mitigé, Claude Opus 4.8 reprend la main. Retour d'expérience concret.
En ce moment je bosse sur la décompilation de Simpsons Hit & Run. Mais je ne repars pas from scratch mais du repo de donut.
J'ai bien avancé avec Deepseek v4 Pro et Claude Opus 4.8.
Jusque là Claude Opus 4.8 avait maintenu le projet fonctionnel.
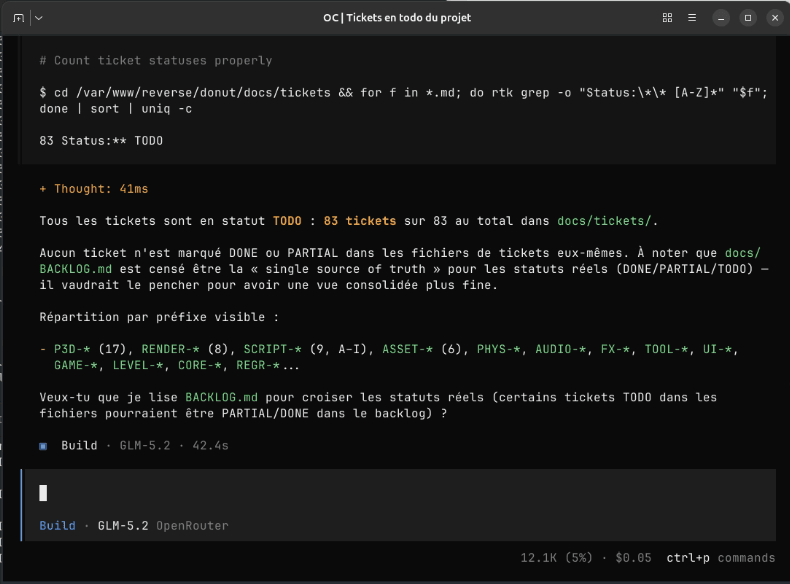
Il en restait 83 dans mon backlog initialement.
J'ai voulu tester GLM 5.2 sur 10 tickets de ce backlog.
Lancement:
Au bout de quelques minutes:
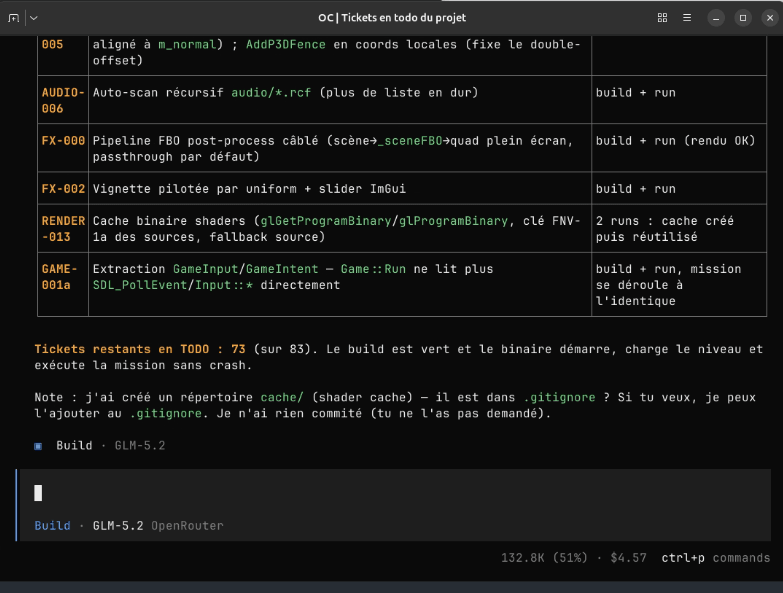
et presque 5$ de consommés pour 140k tokens, je lance le jeu et j'ai un écran noir...
Plus rien ne marche.
J'ai lancé un fix avec Claude Opus 4.8, et il a réglé le problème:
Oui c'est encore un WIP pour le moment.
Mais le test de GLM 5.2 montre que le model n'est pas encore suffisamment autonome sur une codebase dense qu'il ne connait pas.
Bon, je ne désespère pas, je lui donnerai une autre chance prochainement car il n'y avait pas non plus énormément de choses à fixer.
FAQ
GLM 5.2 a-t-il complètement cassé le projet ou juste introduit des bugs ?
Le jeu affichait un écran noir après les modifications de GLM 5.2, donc rien ne fonctionnait plus. Claude Opus 4.8 a suffi à corriger le tir, ce qui suggère des erreurs ciblées plutôt qu'une réécriture catastrophique.
Combien de tickets GLM 5.2 a-t-il traités avant que ça parte en vrille ?
Sur les 10 tickets lancés, GLM 5.2 a consommé environ 140 000 tokens et près de 5 dollars sans produire un résultat stable. Le ratio coût/fiabilité est clairement défavorable par rapport aux autres modèles testés sur ce projet.
Claude Opus 4.8 est-il systématiquement meilleur pour ce type de projet ?
Sur cette codebase dense que les modèles ne connaissent pas nativement, Opus 4.8 s'est montré plus fiable pour maintenir la cohérence du code au fil des tickets. Deepseek v4 Pro a aussi donné de bons résultats, donc le choix dépend aussi du type de tâche.
Pourquoi est-ce plus difficile pour un LLM de travailler sur une codebase inconnue et dense ?
Un modèle doit inférer les conventions, l'architecture et les dépendances implicites sans contexte préalable, ce qui multiplie les risques d'incohérences entre fichiers. Plus la base de code est spécialisée, comme une décompilation de jeu, moins le modèle peut s'appuyer sur des patterns vus à l'entraînement.
GLM 5.2 mérite-t-il un second test ou faut-il l'écarter ?
L'auteur prévoit de lui redonner une chance sur des tâches peut-être mieux délimitées. Un échec sur 10 tickets simultanés ne condamne pas forcément un modèle qui pourrait mieux performer sur des tickets isolés ou moins interdépendants.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.

Poursuivre la lecture

