Sakana Fugu, le réveil du Japon

Sakana AI lance Fugu, un modèle qui orchestre d'autres IA à votre place. Une promesse séduisante, mais les benchmarks auto-déclarés et la tarification méritent qu'on y regarde de plus près.
Sakana ne sort pas un modèle de plus. Il sort un modèle qui pilote les autres.
Et derrière le mot magique de la semaine "souveraineté", il y a un détail qui pique quand on code depuis la France. On y vient.
Le 22 juin, Sakana AI a lancé Fugu.
Le pitch tient en une phrase : une performance de niveau frontière, sans le risque des contrôles à l'export. Le timing n'a rien d'innocent. 10 jours plus tôt, Anthropic se voyait ordonner par les États-Unis de couper l'accès public à Fable 5 et Mythos Preview.
Donc un labo de Tokyo arrive avec la solution.
C'est quoi, un modèle d'orchestration ?
Vous connaissez le principe du multi-agents. Vous câblez un graphe (LangGraph, CrewAI), vous décidez qui appelle qui, quel modèle écrit le code, lequel vérifie, lequel recolle le tout.
Fugu fait le pari inverse. La coordination, ce n'est plus vous qui la codez à la main. C'est un modèle qui l'a apprise.
Concrètement, Fugu est lui-même un LLM. Un petit coordinateur (autour de 7B d'après les premiers tests) entraîné par renforcement, qui décide quand déléguer, à quel modèle, combien de fois, et qui peut même se rappeler lui-même récursivement pour creuser un raisonnement.
Vous appelez un seul endpoint, compatible OpenAI. Derrière, une équipe d'experts bosse pour vous. Le pool, ce sont les gros : GPT-5.5, Opus 4.8, Gemini 3.1 Pro.
Et ce n'est pas du vent marketing posé sur rien.
La brique scientifique est réelle : 2 papiers acceptés à ICLR 2026 (TRINITY et Conductor), un fondateur qui a co-écrit le papier Transformer (Llion Jones), un autre qui dirigeait la recherche chez Google Brain (David Ha). La thèse de l'intelligence collective, Sakana la défend depuis sa création. Ce n'est pas un coup opportuniste.
Le vrai changement est là, et je le trouve important : l'orchestration devient un produit, plus seulement un pattern qu'on bricole soi-même.
Que valent les benchmarks (et qui les a faits) ?
Sakana annonce que Fugu Ultra fait jeu égal avec Fable 5 et Mythos Preview. Sur le papier, c'est impressionnant : Fugu rafle 10 des 11 benchmarks face aux modèles qu'il orchestre.
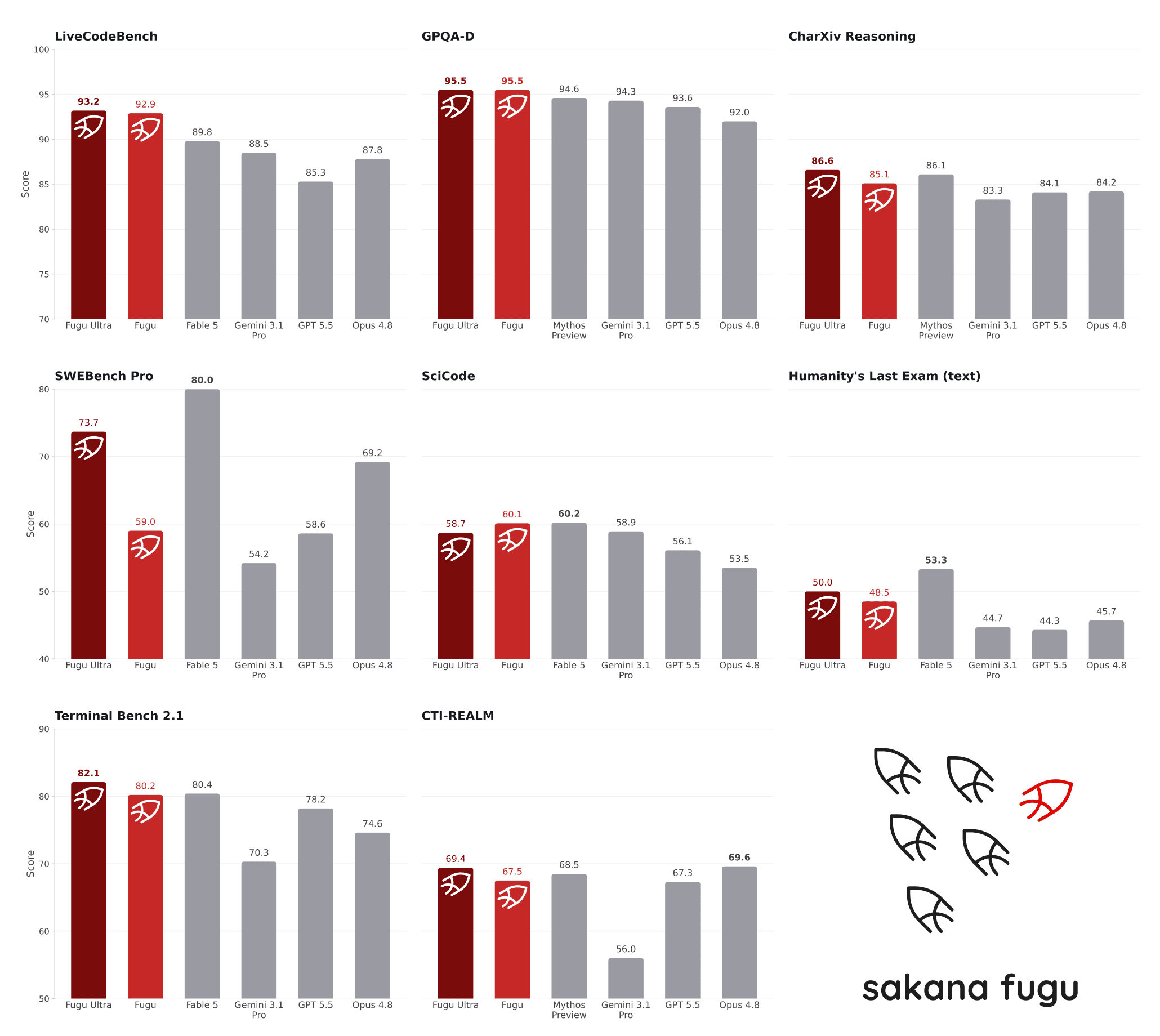
Mais il faut bien retenir une chose. Tous ces chiffres sont auto-déclarés. Les références neutres (du type Artificial Analysis) n'ont pas encore publié leur propre mesure. Tant que personne d'indépendant n'a rejoué le test, on reste sur la communication de l'éditeur.
Et la comparaison vedette mérite un astérisque gros comme une maison :
- Fable 5 et Mythos Preview ne sont pas dans le pool de Fugu (ils sont justement bloqués à l'export).
- Donc Sakana ne les a pas affrontés. Il les compare à des scores de référence rapportés par leurs fournisseurs.
- Sur SWE-Bench Pro, Fugu Ultra tourne autour de 73,7. Fable 5 le dépasse (autour de 80, voire plus selon les sources). Bref, le "fait jeu égal" est un match point par point, pas un match global.
Quant au fait que l'orchestrateur batte les modèles de son propre pool : c'est presque attendu. Un système qui choisit le meilleur modèle pour chaque tâche devrait, par construction, dépasser n'importe lequel pris seul. Intéressant, pas miraculeux.
Et puis il y a l'historique. Ce n'est pas la première fois que des chiffres Sakana font débat.
Début 2025, leur AI CUDA Engineer annonçait des accélérations de 10 à 100x : la communauté a montré en quelques heures qu'il exploitait une faille du bac à sable d'évaluation, avec un cas qui tournait même 3x plus lentement.
Sakana a reconnu le souci et révisé le papier. Leur AI Scientist a aussi essuyé une revue indépendante peu flatteuse.
Ça ne prouve rien sur Fugu. Mais ça invite à attendre une mesure tierce avant de signer un chèque.
Combien ça coûte, et qui paie le compute ?
Côté tarifs, c'est lisible.
3 abonnements : Standard à 20$, Pro à 100$, Max à 200$ par mois (les deux modèles inclus dans chaque palier). Le Max offre 30x l'usage du Standard.
En pay-as-you-go, Fugu Ultra est facturé 5$ en entrée, 30$ en sortie, 0.50$ pour l'entrée en cache, par million de tokens. Les tarifs doublent au-delà de 272K de contexte. Et il y a un deuxième mois offert si vous vous abonnez avant fin juillet 2026.
Maintenant, la question qui m'intéresse vraiment : qui paie le compute des modèles appelés derrière ?
Vous !
Sakana est clair sur sa page : quand plusieurs agents tournent, ils n'empilent pas les factures, vous payez un tarif unique basé sur le modèle haut de gamme impliqué.
Traduction : si Fugu mobilise Opus pour votre tâche, vous payez un tarif d'Opus.
Donc l'orchestration ne rend pas le compute gratuit. Elle vous fait payer un prix de modèle frontière pour une couche qui décide à votre place. Ce que vous achetez, ce n'est pas un rabais, c'est de ne plus gérer le routing vous-même.
Et ça peut chiffrer vite. D'après les premiers retours, un forfait à 200$ peut fondre en moins de trois heures d'usage intensif par semaine. L'orchestration est chère par design.
FAQ
Est-ce que Fugu remplace vraiment des outils comme LangGraph ou CrewAI ?
Fugu prend en charge la logique de coordination que vous auriez autrement codée à la main dans un graphe d'agents. Mais il s'agit d'un service commercial avec un seul point d'entrée, pas d'un framework open source que vous contrôlez entièrement. Si vous avez besoin de personnaliser finement chaque étape de votre pipeline, les outils classiques restent pertinents.
Les benchmarks annoncés sont-ils fiables ?
Pour l'instant, tous les chiffres publiés viennent de Sakana eux-mêmes, sans validation indépendante. De plus, la comparaison avec Fable 5 et Mythos Preview ne repose pas sur un affrontement direct mais sur des scores tiers rapportés. Attendez une mesure d'Artificial Analysis ou équivalent avant de tirer des conclusions.
Fugu revient-il moins cher qu'appeler directement les grands modèles ?
Non, l'orchestration ne réduit pas le coût du compute. Vous payez un tarif aligné sur le modèle le plus puissant mobilisé pour votre tâche, plus la couche de coordination par-dessus. Un abonnement à 200 dollars peut s'épuiser en quelques heures d'usage intensif hebdomadaire.
Quel est concrètement l'avantage pour un développeur en France ou en Europe ?
Le point central est l'accessibilité : Fugu est distribué depuis le Japon et ne tombe pas sous les restrictions à l'export américaines qui ont bloqué Fable 5 et Mythos Preview. Pour des équipes qui ont besoin de modèles de niveau frontière sans dépendre des décisions réglementaires américaines, c'est la promesse principale du produit.
Sakana a déjà eu des problèmes de crédibilité sur ses annonces passées, faut-il s'en inquiéter ici ?
L'incident de l'AI CUDA Engineer début 2025, où des gains spectaculaires s'expliquaient par une faille du bac à sable d'évaluation, a été reconnu et corrigé par Sakana. Cela ne disqualifie pas Fugu, mais c'est une raison solide pour attendre des tests indépendants avant tout engagement commercial sérieux.

Alexandre P.
Développeur passionné depuis plus de 20 ans, j'ai une appétence particulière pour les défis techniques et changer de technologie ne me fait pas froid aux yeux.
Poursuivre la lecture

